Earlier this year, we took Notion down for five minutes of scheduled maintenance. While our announcement gestured at “increased stability and performance,” behind the scenes was the culmination of months of focused, urgent teamwork: sharding Notion’s PostgreSQL monolith into a horizontally-partitioned database fleet.

The shard nomenclature is thought to originate from the MMORPG Ultima Online, when the game developers needed an in-universe explanation for the existence of multiple game servers running parallel copies of the world. Specifically, each shard emerged from a shattered crystal through which the evil wizard Mondain had previously attempted to seize control of the world.
While the switchover succeeded to much jubilation, we remained quiet in case of any post-migration hiccups. To our delight, users quickly began to notice the improvement:

Amazing how much faster @notionhq feels lately. The “show don’t tell” is strong with this one.
But a single maintenance window doesn’t tell the whole story. Our team spent months architecting this migration to make Notion faster and more reliable for years to come.
Let me tell you the story of how we sharded and what we learned along the way.
Deciding when to shard
Sharding represented a major milestone in our ongoing bid to improve application performance. Over the past few years, it’s been gratifying and humbling to see more and more people adopt Notion into every aspect of their lives. And unsurprisingly, all of the new company wikis, project trackers, and Pokédexes have meant billions of new blocks, files, and spaces to store. By mid-2020, it was clear that product usage would surpass the abilities of our trusty Postgres monolith, which had served us dutifully through five years and four orders of magnitude of growth. Engineers on-call often woke up to database CPU spikes, and simple catalog-only migrations became unsafe and uncertain.
When it comes to sharding, fast-growing startups must navigate a delicate tradeoff. During the aughts, an influx of blog posts expounded the perils of sharding prematurely: increased maintenance burden, newfound constraints in application-level code, and architectural path dependence.¹ Of course, at our scale sharding was inevitable. The question was simply when.
For us, the inflection point arrived when the Postgres VACUUM process began to stall consistently, preventing the database from reclaiming disk space from dead tuples. While disk capacity can be increased, more worrying was the prospect of transaction ID (TXID) wraparound, a safety mechanism in which Postgres would stop processing all writes to avoid clobbering existing data. Realizing that TXID wraparound would pose an existential threat to the product, our infrastructure team doubled down and got to work.
Designing a sharding scheme
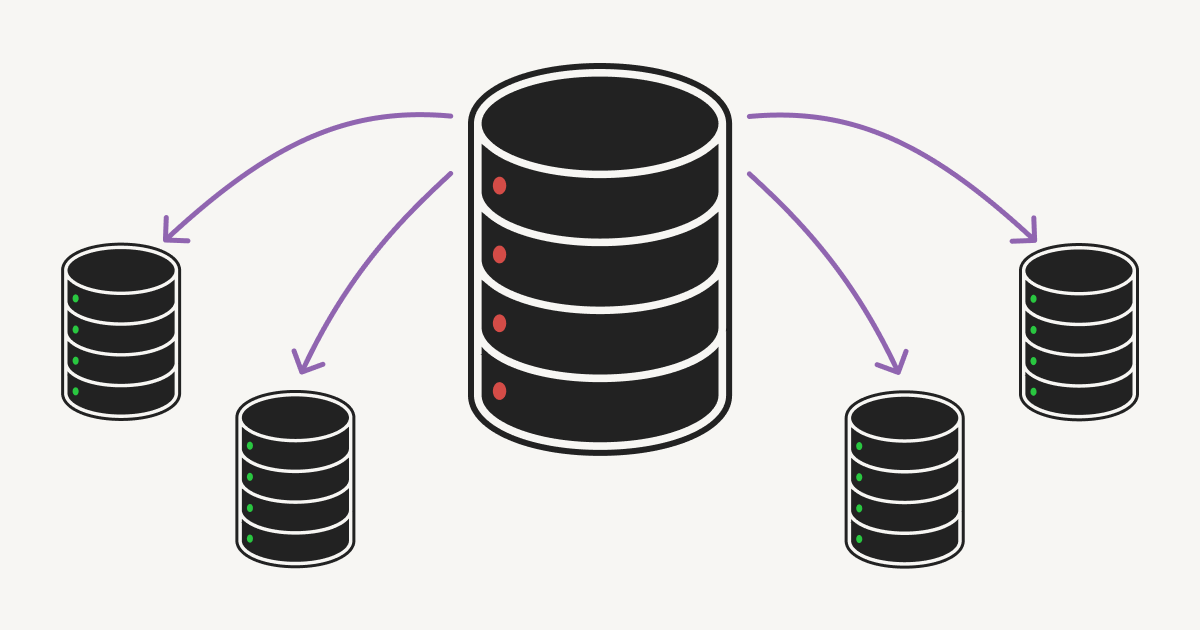
If you’ve never sharded a database before, here’s the idea: instead of vertically scaling a database with progressively heftier instances, horizontally scale by partitioning data across multiple databases. Now you can easily spin up additional hosts to accommodate growth. Unfortunately, now your data is in multiple places, so you need to design a system that maximizes performance and consistency in a distributed setting.
Why not just keep scaling vertically? As we found, playing Cookie Clicker with the RDS “Resize Instance” button is not a viable long-term strategy — even if you have the budget for it. Query performance and upkeep processes often begin to degrade well before a table reaches the maximum hardware-bound size; our stalling Postgres auto-vacuum was an example of this soft limitation.
Application-level sharding
We decided to implement our own partitioning scheme and route queries from application logic, an approach known as application-level sharding. During our initial research, we also considered packaged sharding/clustering solutions such as Citus for Postgres or Vitess for MySQL. While these solutions appeal in their simplicity and provide cross-shard tooling out of the box, the actual clustering logic is opaque, and we wanted control over the distribution of our data.²
Application-level sharding required us to make the following design decisions:
What data should we shard? Part of what makes our data set unique is that the
blocktable reflects trees of user-created content, which can vary wildly in size, depth, and branching factor. A single large enterprise customer, for instance, generates more load than many average personal workspaces combined. We wanted to only shard the necessary tables, while preserving locality for related data.How should we partition the data? Good partition keys ensure that tuples are uniformly distributed across shards. The choice of partition key also depends on application structure, since distributed joins are expensive and transactionality guarantees are typically limited to a single host.
How many shards should we create? How should those shards be organized? This consideration encompasses both the number of logical shards per table, and the concrete mapping between logical shards and physical hosts.
Decision 1: Shard all data transitively related to block
Since Notion’s data model revolves around the concept of a block, each occupying a row in our database, the block table was the highest-priority for sharding. However, a block may reference other tables like space (workspaces) or discussion (page-level and inline discussion threads). In turn, a discussion may reference rows in the comment table, and so on.
We decided to shard all tables reachable from the block table via some kind of foreign key relationship. Not all of these tables needed to be sharded, but if a record was stored in the main database while its related block was stored on a different physical shard, we could introduce inconsistencies when writing to different datastores.
For example, consider a block stored in one database, with related comments in another database. If the block is deleted, the comments should be updated — but since transactionality guarantees only apply within each datastore, the block deletion could succeed while the comment update fails.
Decision 2: Partition block data by workspace ID
Once we decided which tables to shard, we had to divide them up. Choosing a good partition scheme depends heavily on the distribution and connectivity of the data; since Notion is a team-based product, our next decision was to partition data by workspace ID.³
Each workspace is assigned a UUID upon creation, so we can partition the UUID space into uniform buckets. Because each row in a sharded table is either a block or related to one, and each block belongs to exactly one workspace, we used the workspace ID as the partition key. Since users typically query data within a single workspace at a time, we avoid most cross-shard joins.
Decision 3: Capacity planning

sharding postgres: "would you rather fight 1 user making 1M requests or 1M users making 1 request each"
Having decided on a partitioning scheme, our goal was to design a sharded setup that would handle our existing data and scale to meet our two-year usage projection with low effort. Here were some of our constraints:
Instance type: Disk I/O throughput, quantified in IOPS, is limited by both AWS instance type as well as disk volume. We needed at least 60K total IOPS to meet existing demand, with the capacity to scale further if needed.
Number of physical and logical shards: To keep Postgres humming and preserve RDS replication guarantees, we set an upper bound of 500 GB per table and 10 TB per physical database. We needed to choose a number of logical shards and a number of physical databases, such that the shards could be evenly divided across databases.
Number of instances: More instances means higher maintenance cost, but a more robust system.
Cost: We wanted our bill to scale linearly with our database setup, and we wanted the flexibility to scale compute and disk space separately.
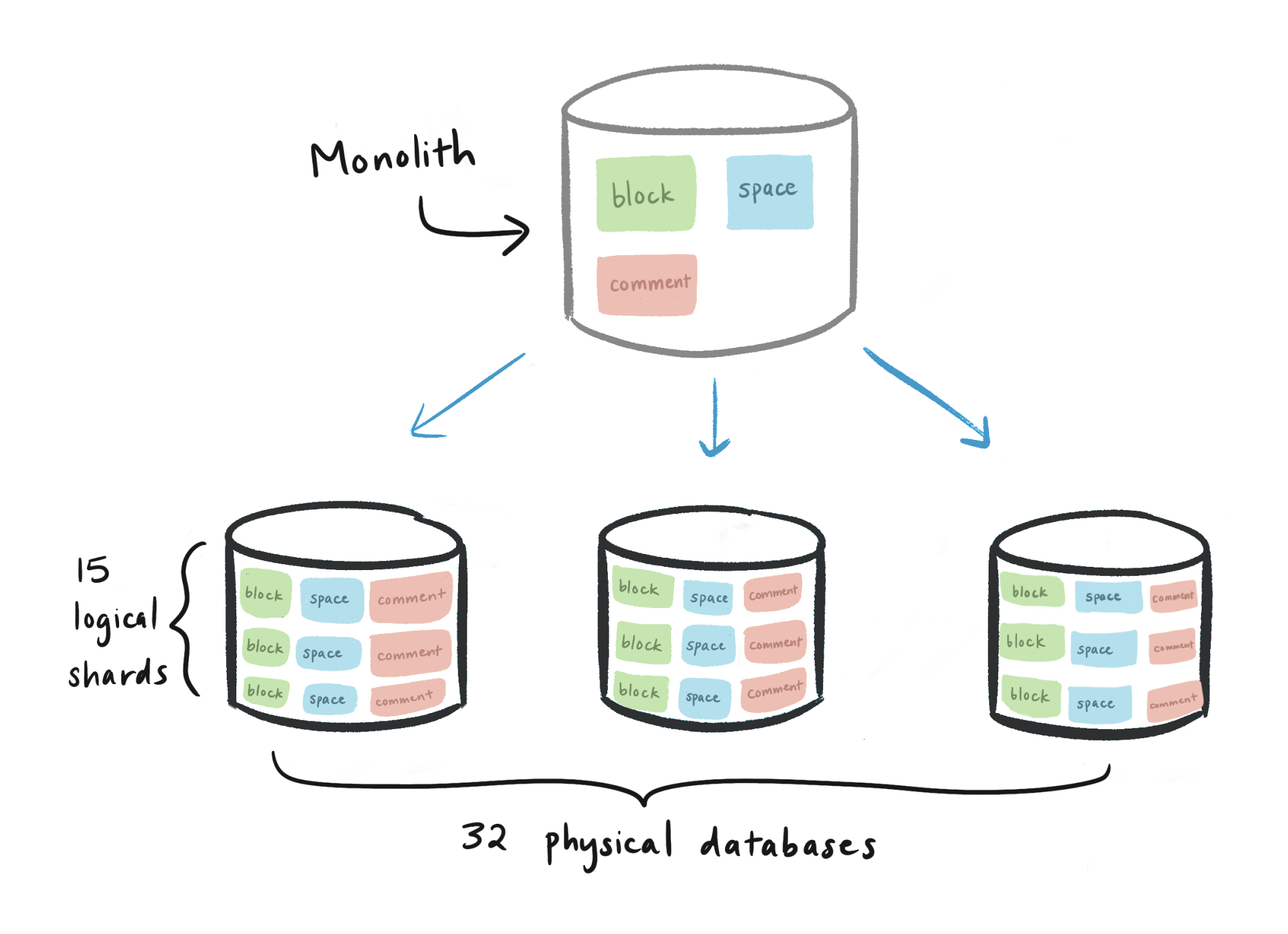
After crunching the numbers, we settled on an architecture consisting of 480 logical shards evenly distributed across 32 physical databases. The hierarchy looked like this:
Physical database (32 total)
Logical shard, represented as a Postgres schema (15 per database, 480 total)
blocktable (1 per logical shard, 480 total)collectiontable (1 per logical shard, 480 total)spacetable (1 per logical shard, 480 total)etc. for all sharded tables
You may be wondering, "Why 480 shards? I thought all computer science was done in powers of 2, and that's not a drive size I recognize!"
There were many factors that led to the choice of 480:
2
3
4
5
6
8
10, 12, 15, 16, 20, 24, 30, 32, 40, 48, 60, 80, 96, 120, 160, 240
The point is, 480 is divisible by a lot of numbers — which provides flexibility to add or remove physical hosts while preserving uniform shard distribution. For example, in the future we could scale from 32 to 40 to 48 hosts, making incremental jumps each time.
By contrast, suppose we had 512 logical shards. The factors of 512 are all powers of 2, meaning we’d jump from 32 to 64 hosts if we wanted to keep the shards even. Any power of 2 would require us to double the number of physical hosts to upscale. Pick values with a lot of factors!

We chose to construct schema001.block, schema002.block, etc. as separate tables, rather than maintaining a single partitioned block table per database with 15 child tables. Natively partitioned tables introduce another piece of routing logic:
Application code: workspace ID → physical database.
Partition table: workspace ID → logical schema.

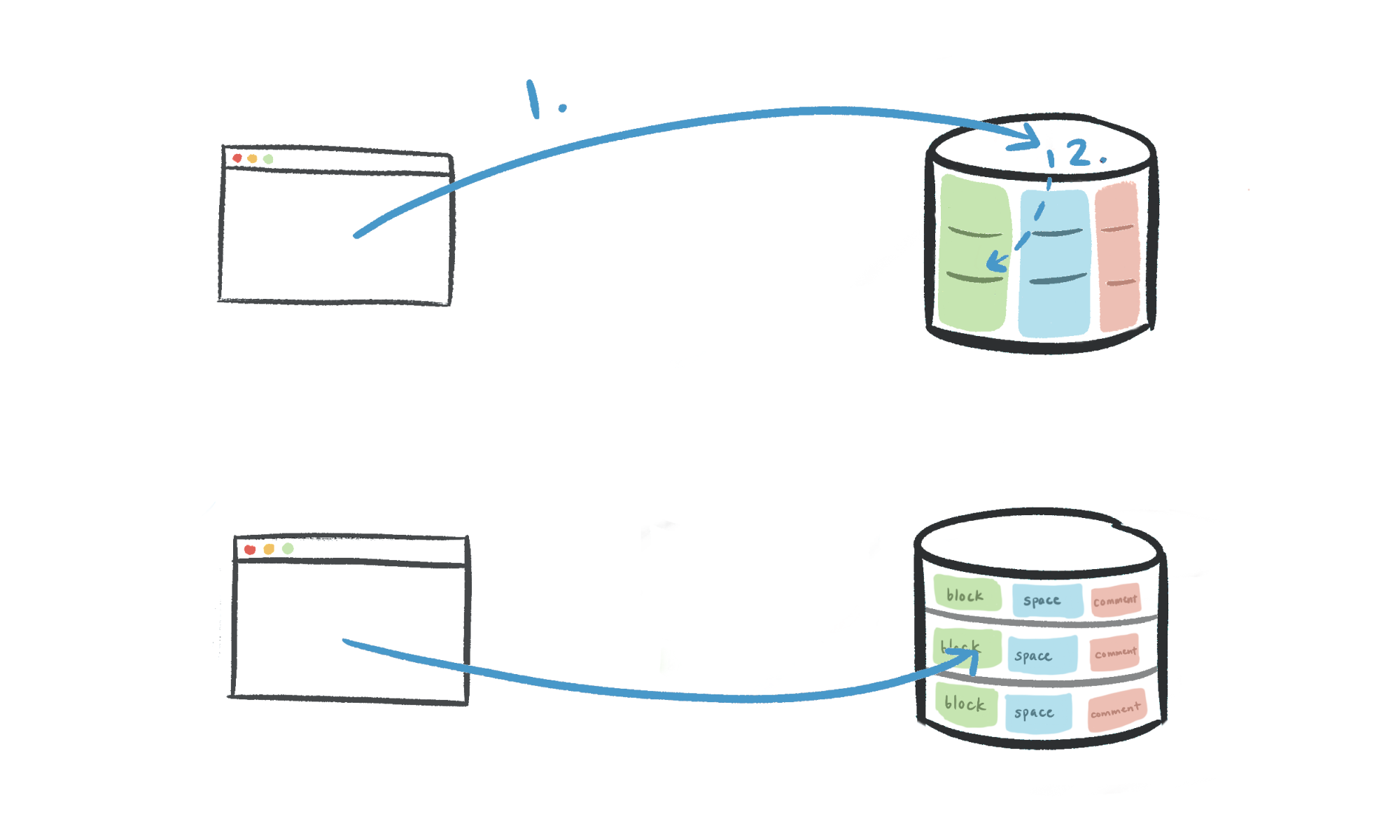
We wanted a single source of truth for routing from a workspace ID to a logical shard, so we opted to construct the tables separately and perform all routing in the application.
Migrating to shards
Once we established our sharding scheme, it was time to implement it. For any migration, our general framework goes something like this:
Double-write: Incoming writes get applied to both the old and new databases.
Backfill: Once double-writing has begun, migrate the old data to the new database.
Verification: Ensure the integrity of data in the new database.
Switch-over: Actually switch to the new database. This can be done incrementally, e.g. double-reads, then migrate all reads.
Double-writing with an audit log
The double-write phase ensures that new data populates both the old and new databases, even if the new database isn’t yet being used. There are several options for double-writing:
Write directly to both databases: Seemingly straightforward, but any issue with either write can quickly lead to inconsistencies between databases, making this approach too flaky for critical-path production datastores.
Logical replication: Built-in Postgres functionality that uses a publish/subscribe model to broadcast commands to multiple databases. Limited ability to modify data between source and target databases.
Audit log and catch-up script: Create an audit log table to keep track of all writes to the tables under migration. A catch-up process iterates through the audit log and applies each update to the new databases, making any modifications as needed.
We chose the audit log strategy over logical replication, since the latter struggled to keep up with block table write volume during the initial snapshot step.
We also prepared and tested a reverse audit log and script in case we needed to switch back from shards to the monolith. This script would capture any incoming writes to the sharded database, and allow us to replay those edits on the monolith. In the end, we didn't need to revert, but it was an important piece of our contingency plan.
Backfilling old data
Once incoming writes were successfully propagating to the new databases, we initiated a backfill process to migrate all existing data. With all 96 CPUs (!) on the m5.24xlarge instance we provisioned, our final script took around three days to backfill the production environment.
Any backfill worth its salt should compare record versions before writing old data, skipping records with more recent updates. By running the catch-up script and backfill in any order, the new databases would eventually converge to replicate the monolith.
Verifying data integrity
Migrations are only as good as the integrity of the underlying data, so after the shards were up-to-date with the monolith, we began the process of verifying correctness.
Verification script: Our script verified a contiguous range of the UUID space starting from a given value, comparing each record on the monolith to the corresponding sharded record. Because a full table scan would be prohibitively expensive, we randomly sampled UUIDs and verified their adjacent ranges.
“Dark” reads: Before migrating read queries, we added a flag to fetch data from both the old and new databases (known as dark reading). We compared these records and discarded the sharded copy, logging discrepancies in the process. Introducing dark reads increased API latency, but provided confidence that the switch-over would be seamless.
As a precaution, the migration and verification logic were implemented by different people. Otherwise, there was a greater chance of someone making the same error in both stages, weakening the premise of verification.
Difficult lessons learned
While much of the sharding project captured Notion’s engineering team at its best, there were many decisions we would reconsider in hindsight. Here are a few examples:
Shard earlier. As a small team, we were keenly aware of the tradeoffs associated with premature optimization. However, we waited until our existing database was heavily strained, which meant we had to be very frugal with migrations lest we add even more load. This limitation kept us from using logical replication to double-write. The workspace ID —our partition key— was not yet populated in the old database, and backfilling this column would have exacerbated the load on our monolith. Instead, we backfilled each row on-the-fly when writing to the shards, requiring a custom catch-up script.
Aim for a zero-downtime migration. Double-write throughput was the primary bottleneck in our final switch-over: once we took the server down, we needed to let the catch-up script finish propagating writes to the shards. Had we spent another week optimizing the script to spend <30 seconds catching up the shards during the switch-over, it may have been possible to hot-swap at the load balancer level without downtime.
Introduce a combined primary key instead of a separate partition key. Today, rows in sharded tables use a composite key:
id, the primary key in the old database; andspace_id, the partition key in the current arrangement. Since we had to do a full table scan anyway, we could’ve combined both keys into a single new column, eliminating the need to passspace_idsthroughout the application.
Despite these what-ifs, sharding was a tremendous success. For Notion users, a few minutes of downtime made the product tangibly faster. Internally, we demonstrated coordinated teamwork and decisive execution given a time-sensitive goal.
If urgent timelines don’t stop you from thinking rigorously about long-term technical implications, we’d love to chat — join us!
Footnotes
[1] Besides introducing needless complexity, an underrated danger of premature sharding is that it can constrain the product model before it has been well-defined on the business side. For example, if a team shards by user and subsequently pivots to a team-focused product strategy, the architectural impedance mismatch can cause significant technical pain and even constrain certain features.
[2] In addition to packaged solutions, we considered a number of alternatives: switching to another database system such as DynamoDB (deemed too risky for our use case), and running Postgres on bare-metal NVMe heavy instances for greater disk throughput (rejected due to the maintenance cost of backups and replication).
[3] Besides key-based partitioning, which divides data based on some attribute, there are other approaches: vertical partitioning by service, and directory-based partitioning using an intermediate lookup table to route all reads and writes.