Earlier this year, we swapped out Notion’s live database cluster for a larger one without taking downtime.
We added far more machines to the new cluster compared to its previous generation, which was at-risk due to a significant increase in traffic since our last capacity overhaul. Notion users likely didn’t notice this complicated failover (the details about which will follow) because we designed the process to not require downtime, keeping Notion up for an ever-more-global Notion community.
This post is about why and how we horizontally re-sharded our databases. Before we jump in, let’s start with a quick primer on Notion’s database architecture.
A brief history of Notion’s database architecture
We’ve evolved Notion's database architecture several times to keep up with the rapid growth of our user base. In the early days, we relied on a single, beefy Postgres database on Amazon RDS (the largest available at the time, in fact). As usage grew, we horizontally sharded that database to handle the increasingly large load — read about that in our previous post.

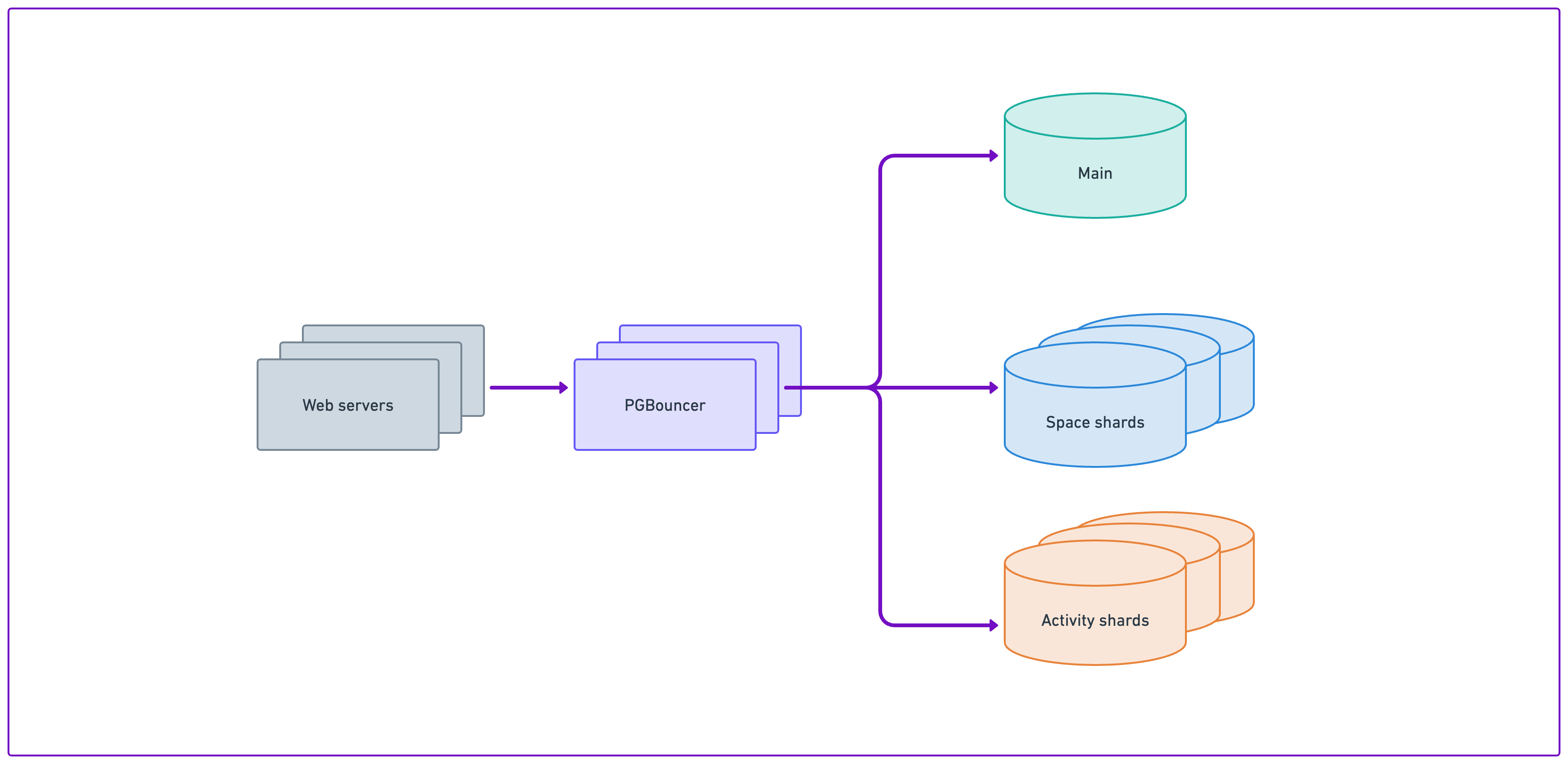
Between our application web servers and the databases, a proxy layer (PgBouncer) pools connections to the databases. The web servers connect to PgBouncer, which then connects to the databases, which respond to queries sent from the application.
There are now multiple database clusters that are essential to Notion’s product, but the one we’ll be discussing here is called the “space shards.” Prior to our work here, this cluster consisted of 32 databases which store all the content generated inside a Notion workspace, including blocks, comments, collections (i.e., “Notion databases”), and so on. The data are partitioned by workspace ID.

When you create a new workspace in Notion, the workspace is assigned a random unique ID, which maps your workspace on one of the 32 database shards. From then on, all the data for your workspace is stored on the same shard to enable a speedy user experience.
Running out of headroom
The 32-machine space shard world served us well for a while. But Notion continued to grow, and so intensified the load on the 32 hosts. As a result, toward the end of 2022 we started noticing several problems:
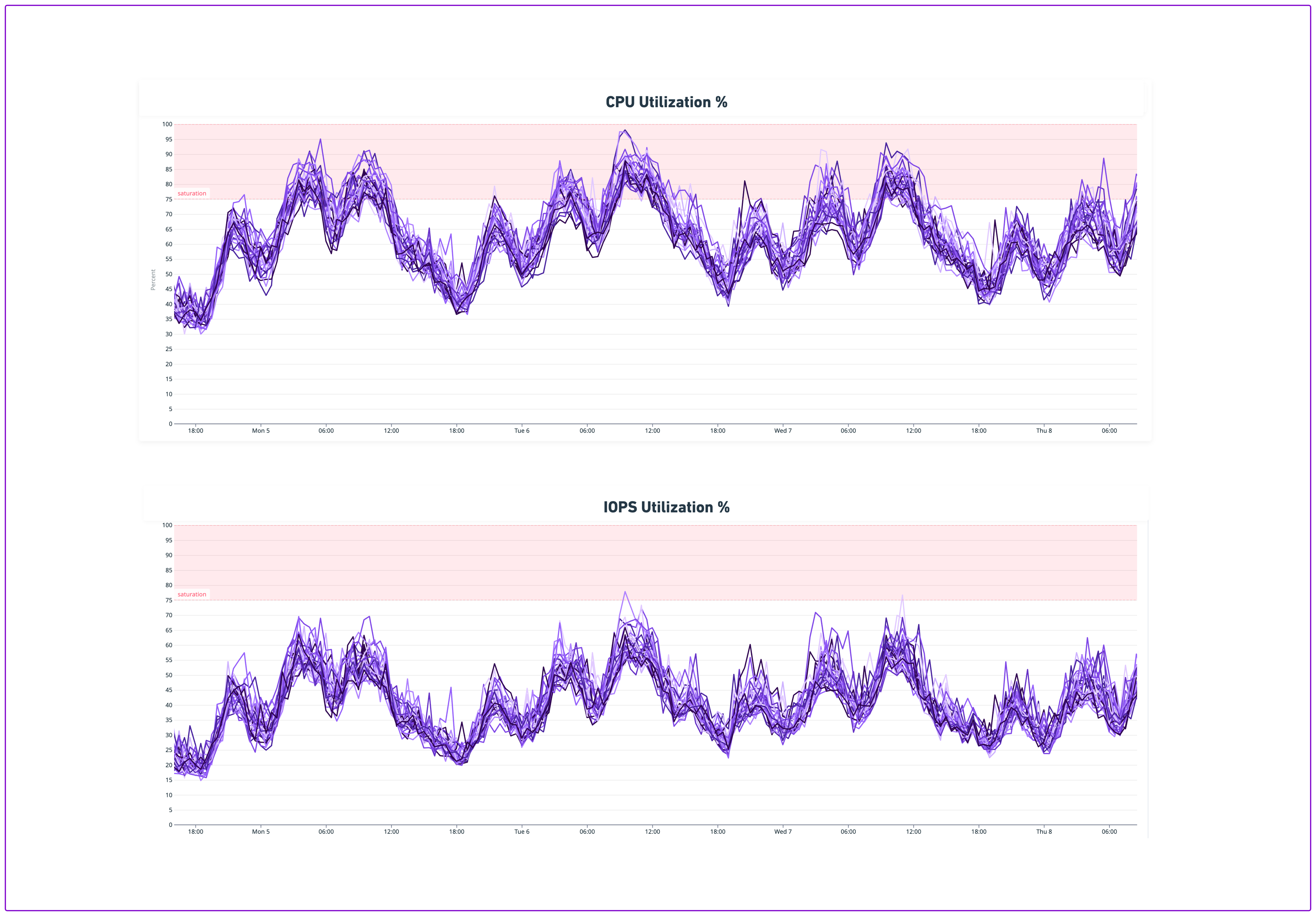
Some of the shards were exceeding 90% CPU utilization at peak traffic
Many were also nearing full utilization of provisioned disk bandwidth (IOPS)
We were running into connection limits scaling our PgBouncer deployment
With an anticipated new-year traffic spike — historically, we’ve seen dramatic spikes in sign-ups and usage in the new year — we knew we were at risk.

What could we do? The availability, performance, and scalability of these machines are critical to Notion’s core experience, each serving a large chunk of Notion’s user base and quickly running out of capacity. We needed to take action quickly and carefully.
Solution: Add more databases!
After evaluating multiple solutions, we decided that horizontal resharding was the best way to increase our database capacity. We considered scaling vertically onto larger machines, but we knew we’d run into the same limitations in the future, ultimately forcing us to horizontally scale. On top of that, distributing load across more machines meant we’d be able to tune the discrete instances to match their traffic since some shards experience greater load than others. We wouldn’t get this benefit with vertical scaling.
Concretely, horizontal scaling meant splitting the databases into smaller shards, allowing us to distribute the heavy load across more machines and improve performance.

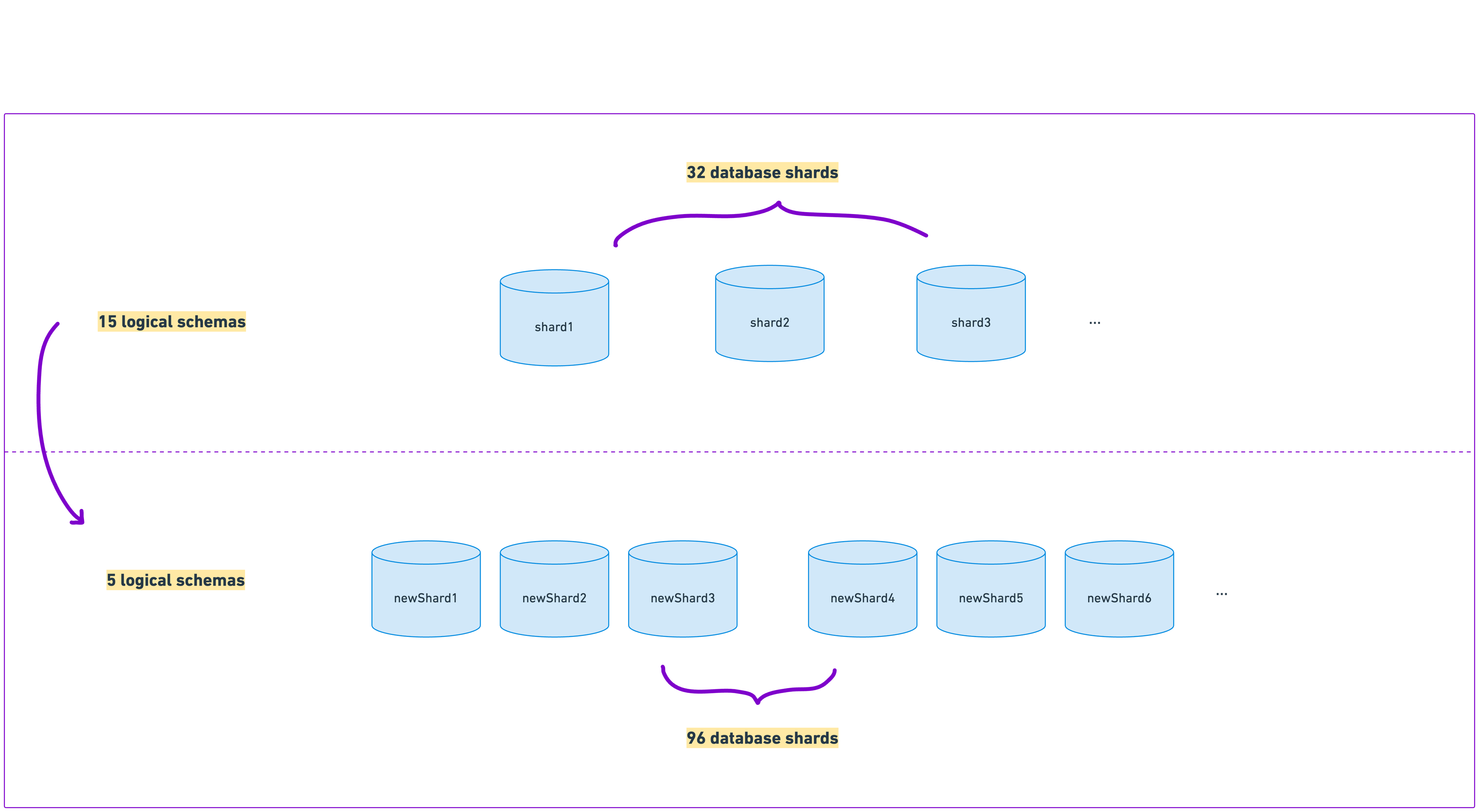
After going through a capacity planning exercise, we landed on tripling the number of instances in our fleet from 32 to 96 machines. This allowed us to comfortably handle our expected traffic growth and reduce both CPU and IOPS utilization dramatically, giving us headroom to endure the spike and many months into the future.
Additionally, we provisioned smaller instances and disks for the new shards to keep costs under control. For example, there was no need to triple the amount of disk storage since we could easily increase disk size later and it is not currently a bottleneck for us.
In the following sections, we'll walk through implementations for
Horizontally re-sharding our Postgres fleet, and
An important detour to shard our PgBouncer connection-pooling layer
Throughout, we’ll cover the challenges we faced and the lessons we learned.
Implementation
Setting up the new shards
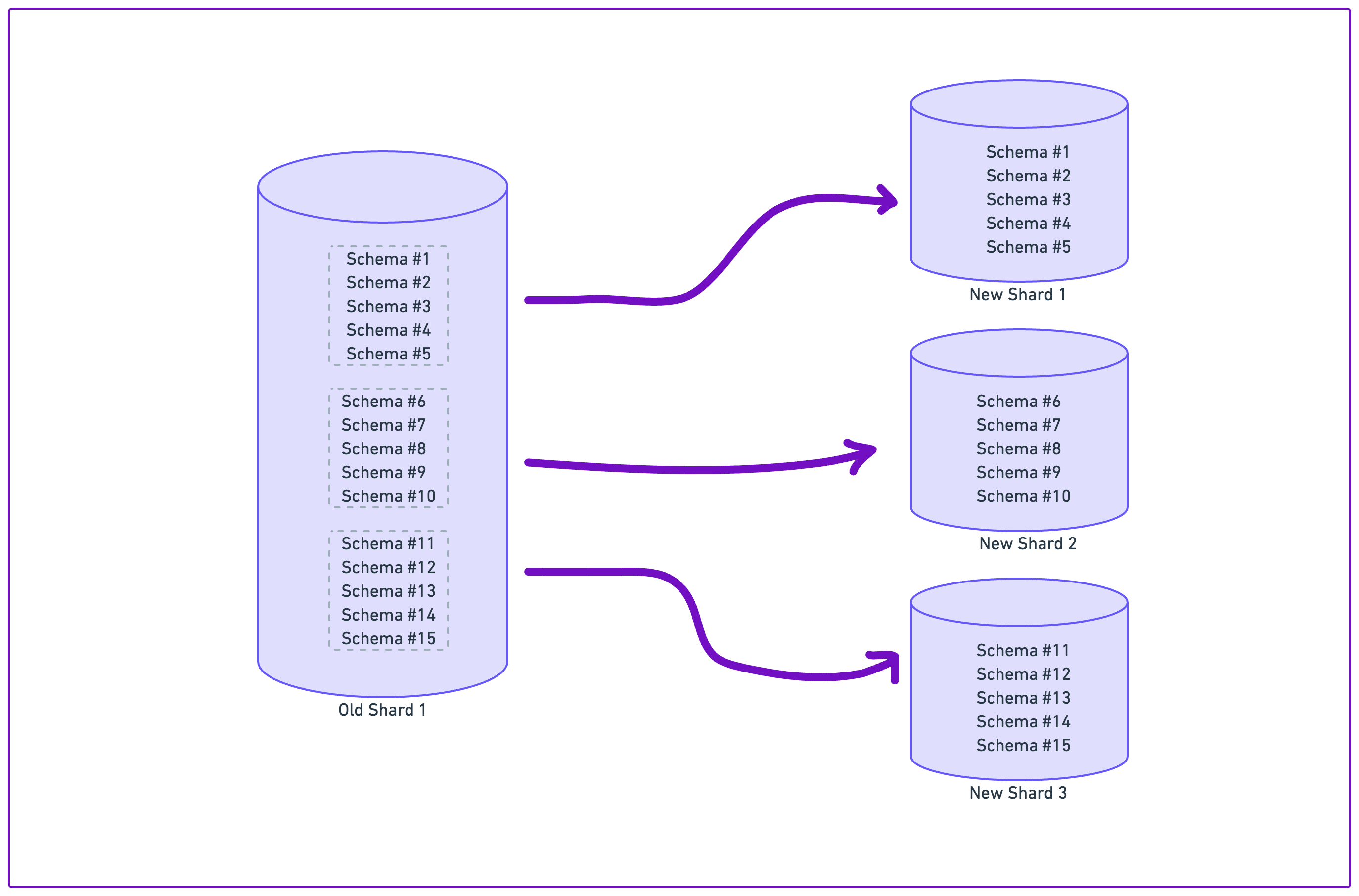
The first step was to provision a new database cluster and define the schemas for each of its instances. Recall that we were able to build on top of our existing architecture, which partitions data into 15 separate logical schemas per database.
To distribute the load across more machines, we simply divided the existing logical schema partitions across more machines. Since we chose a scaling factor of 3x, we went from having 15 schemas per shard to 5.

We used Terraform to automate the provisioning process and configured the new databases with the smaller instance types and disks, since they now would each need to handle much less traffic.
Synchronizing the data across new and old shards
Once the new databases were set up, we started copying all the production data into the new shards. We used built-in Postgres logical replication to copy over the historical data and continuously apply new changes to the new databases. We needed to replicate the data from the old databases to the new ones while keeping them in sync.
We wrote tooling to set up 3 Postgres publications on each existing database, covering 5 logical schemas apiece. We added all the tables from the respective logical schemas to the publications. On the new databases, we simply created subscriptions to consume one of the 3 publications, which copied over the relevant set of data.
We closely monitored the replication process to ensure that there was no data loss or corruption. We also performed several tests to ensure that the new databases could handle the replication traffic and maintain their performance.
💡 One interesting learning in this phase was that the copy process went significantly faster when we skipped creating indexes when setting up the new database. Once the data finished copying over, we rebuilt the indexes.
Total time to synchronize the machines decreased from 3 days to 12 hours!
Verification
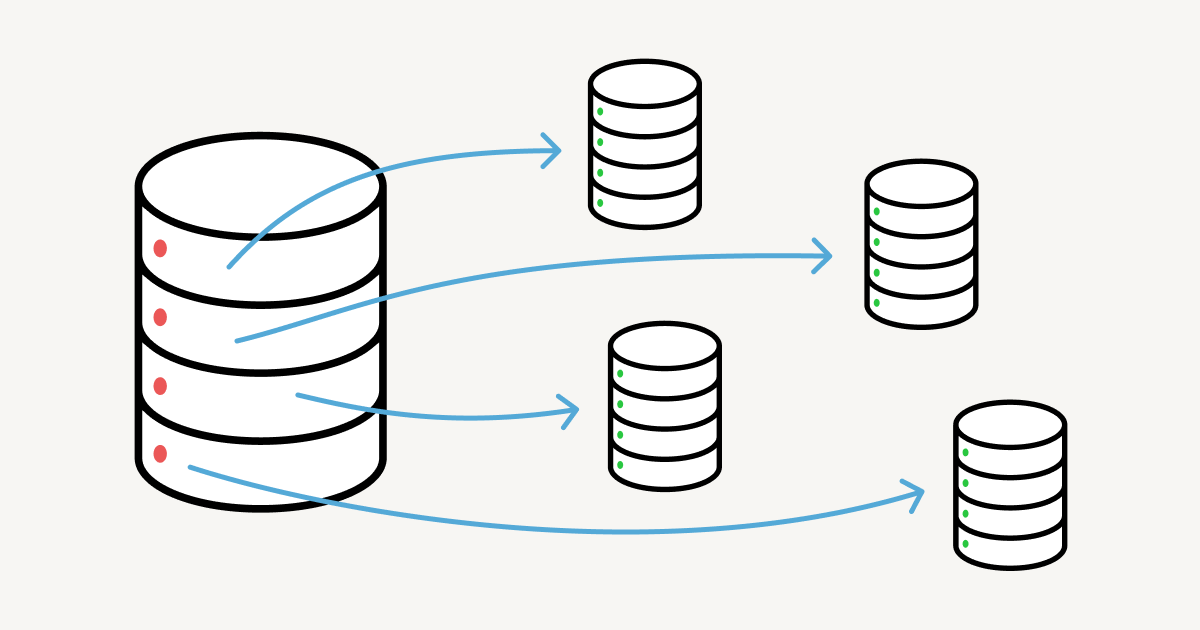
Once the replication was complete and the new shards were caught up with the live shards, our next step was to start using the 96 new shards in our application codebase.
Because we use PgBouncer as our load balancer for Postgres traffic, we could easily add the new database entries for the 96 shards and redirect them back to the existing 32 shards and slowly migrate traffic over as we verified the results.
This diagram shows conceptually how all of this would work.

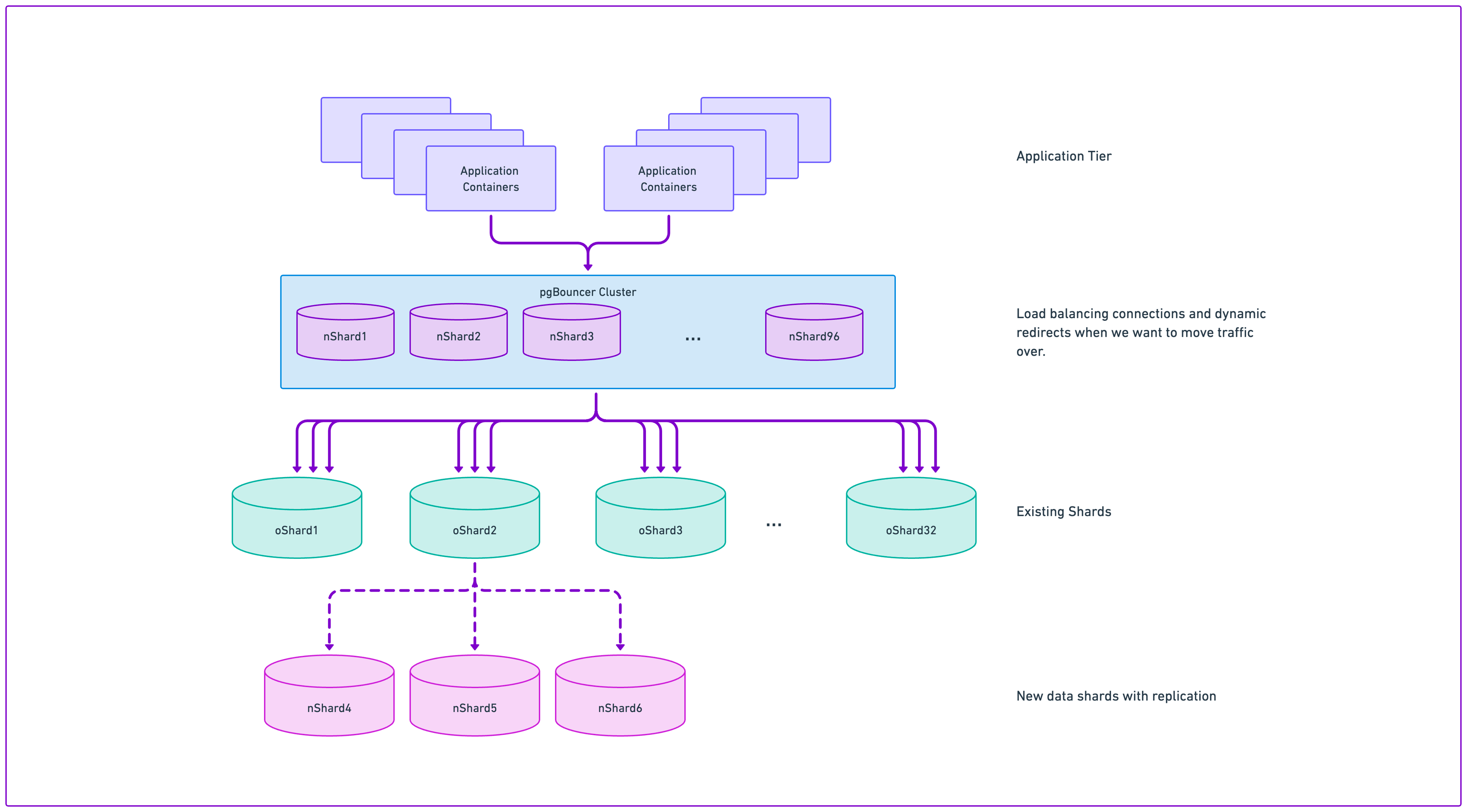
We started testing this process with a single shard first, creating the 3 new entries for the new shards and pointing them to the existing database. This immediately exposed a new problem, as we would have to either cut the number of downstream server connections by a similar factor to account for the load, or increase our total connections per database by 3x.
Specifically, we had about 100 PgBouncer instances, each of which could open up to 6 connections to each space shard (as well as some connections to other unsharded databases), for a total of 600 connections to each shard.
Increasing that number requires care — too many open connections can overwhelm the database, and if we simply increased the number of databases, we’d end up with each PgBouncer instance opening 18 connections to each old shard during the time after we set up for the migration, but before the cutover.


We could have reduced the number of connections to each new shard to avoid this issue, but testing confirmed our suspicions: too few connections and our queries would get backed up.


The solution was to first shard our PgBouncer cluster. Instead of having a single cluster that talked to all our databases, we’d have one cluster for each unsharded database, plus clusters for each group of space shards — we split them into 4 groups, with 24 databases downstream of each PgBouncer shard. (We could have gone all the way to a cluster per shard, but that would make our clusters so small as to cause other problems.)


After the change, we could not only make it through the migration, but we also have a lot more room to scale up the PgBouncer cluster further when we need to.
We rolled out this change using a similar approach to the main sharding, but in miniature: this time, instead of making the updates in PgBouncer, we made them in the load balancer. We had to do the updates as many small steps to avoid overwhelming the database at any point, but luckily, PgBouncer is fairly stateless, so the migration just meant moving new traffic over, then waiting for connections to drain. After that migration was done, we were ready to proceed to the main event — the failover to the new databases.

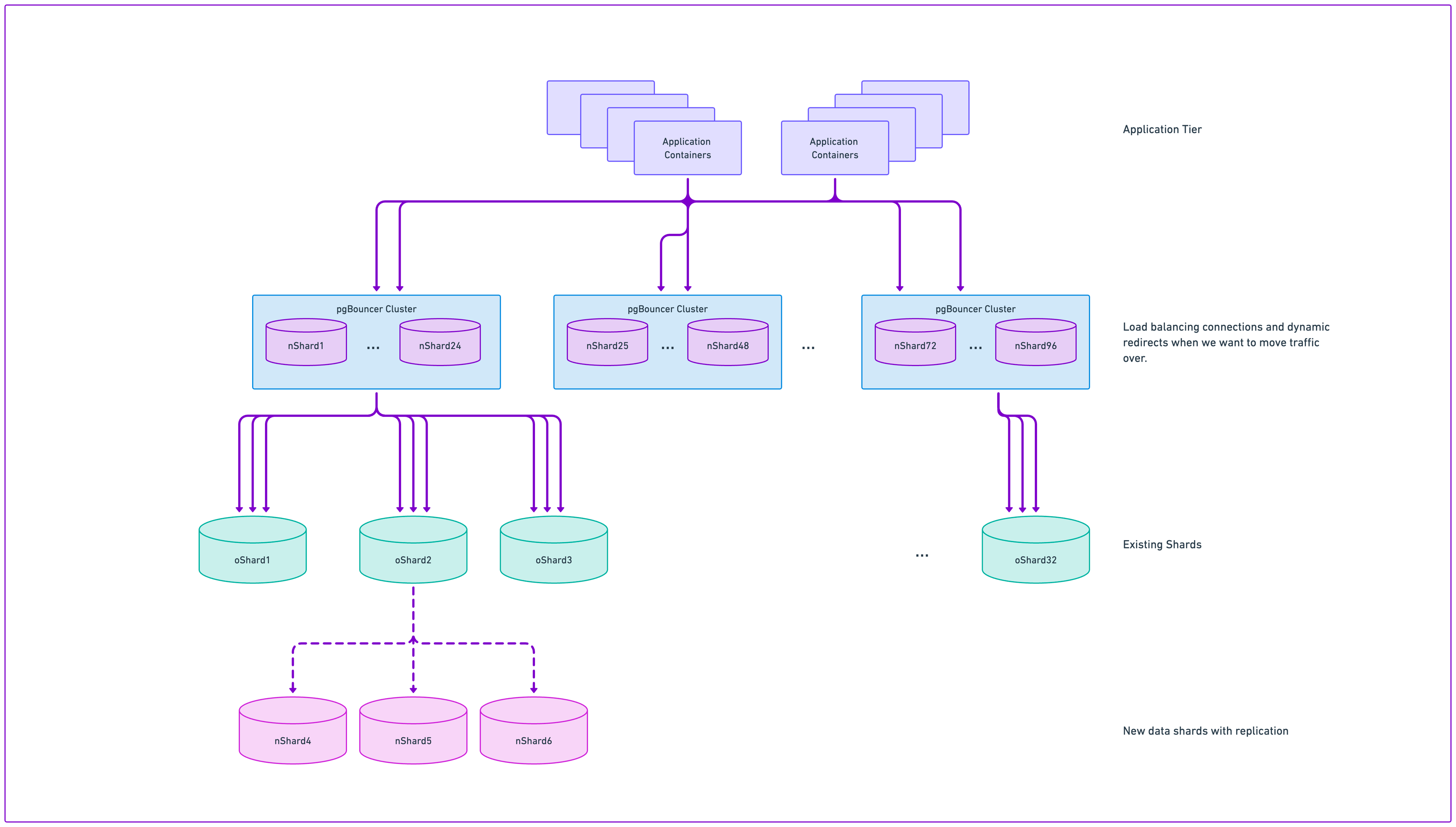
Testing with Dark Reads
We successfully re-sharded PgBouncer to handle the new connection load, but before we started failing over to the new shards in production, we wanted to run some additional tests.
For example, we ran the whole process above in our staging environment first, in order to ensure that the tooling worked as we expected and there was no perceived downtime.
We also wanted to confirm that the new machines were catching up with the logical replication stream and verify there was no data corruption. For this we used dark reads.
📖 Dark read: A parallel read query issued to a follower database, whose results we can compare with those of the primary to ensure equality (i.e., the follower’s dataset matches the primary).
Put simply, we wanted to double-check that we’d get the same results from the new database as we would from the existing one, provided we give a small buffer for replication to catch up.
We learned two key things from this.
First, we found that any extra CPU work we added to our main query code path could, when scaled up to our production traffic, cause meaningful latency for our end users. To avoid that, we scoped the comparison to queries returning up to 5 rows from the database, and only compared the results for a small sampling of requests.
Second, to confirm that the followers had enough time to catch up with the write-ahead log (the stream of changes published by Postgres for logical replication), we used a simple setTimeout in our NodeJS web server to force a 1 second pause for replication to catch up before issuing the dark read query, comparing result equality, and emitting the metrics to Datadog.
Ultimately, we saw near 100% equivalence with our dark read and primary read samples, so we were confident to fail over (the remaining percentage was probably from nondeterministic queries like limit or extended replication lag).
Failover
The details of the failover process are quite interesting.

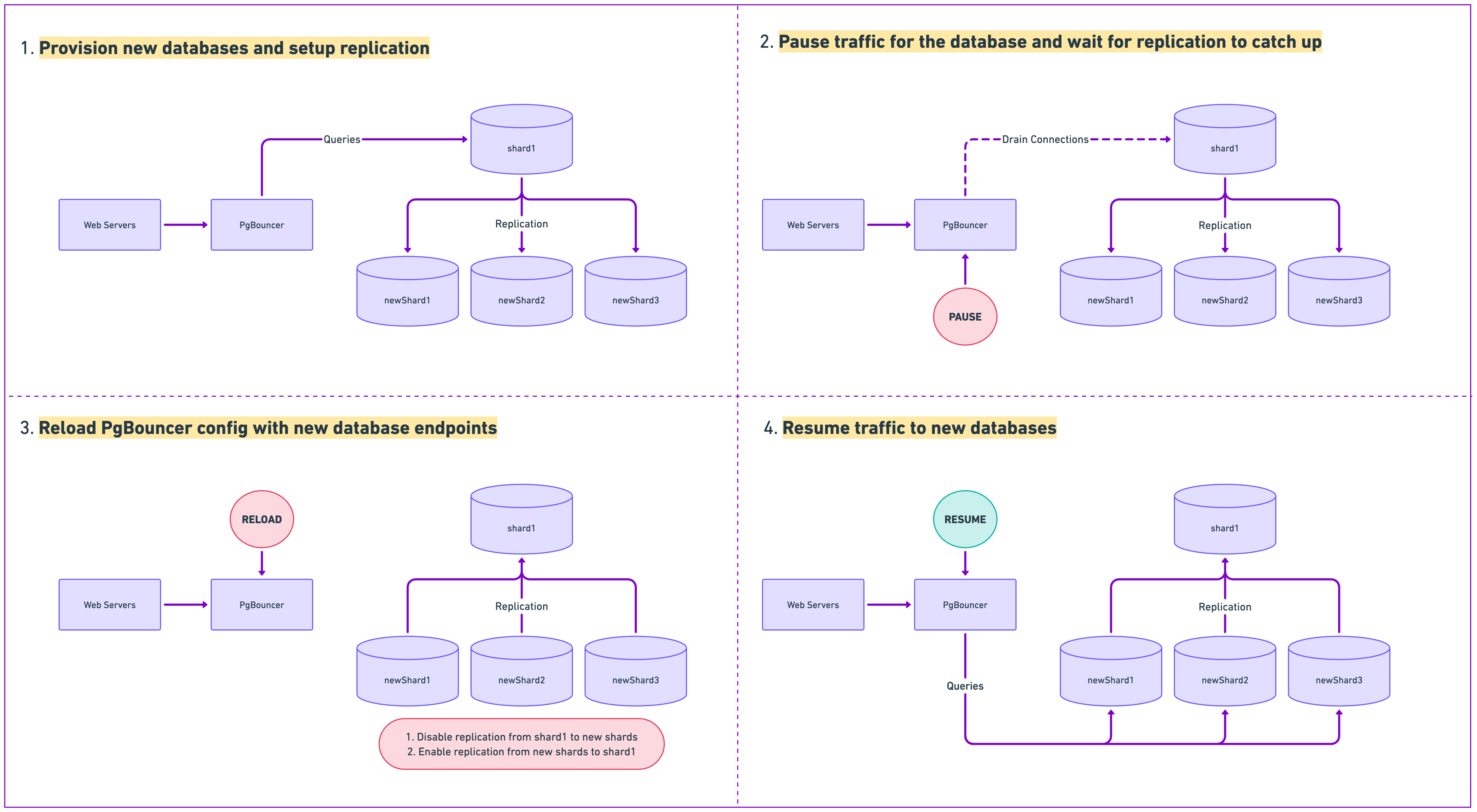
At a high level, we ran the following steps on each database, using a script to issue the PgBouncer commands.
Pause all traffic for the existing database in our PgBouncer cluster. Stop accepting client connections, and allow server connections to finish their queries.
Verify that replication has caught up on the new databases. i.e., that no data is lost.
Once replication catches up, update the PgBouncer shard mapping to point to the new database URLs. Reload PgBouncer to start using the new config. In this step, we also revoke login access to the old database from our application, and flip replication streams so that the new databases are replicating back to the old database.
Resume traffic to the new shards.
Each step has checkpoints and the ability to roll back, and we need to run it for each database in our fleet.
The reverse replication stream gave us a lot of confidence that we could roll back our solution in case of unexpected problems. We tested this entire process multiple times on our staging environment before proceeding with production.
So, how did it go?
Smoothly! We ran our scripts carefully on each of the new 96 shards. For each failover, we observed a healthy transition of reads and writes on the new shards, giving us confidence that traffic had cut over successfully. We also verified there were no writes from our application user going to the old shards after failover, but that it was consuming the write-ahead log of the new shard in case we ever needed to rollback.
Best of all, there was no report or observation in our metrics of perceived user downtime. At worst, a user would have experienced about a second of a “saving” loading spinner while the failover was waiting for queries to finish, updating configs, swapping the replication stream, and reloading our proxy layer to send queries to the new shards.
Conclusion
By extending our horizontal sharding and adding more database clusters, we were able to scale our system to handle the increased load and provide a better experience for our users. We followed a careful migration plan that ensured that there was no observable downtime, no data loss or corruption, and that the migration was completed in a reasonable amount of time.
Throughout the process, we faced several challenges and learned several lessons. We learned the importance of careful planning, monitoring, and testing when implementing large-scale changes to a system. We also learned the importance of automation and scalability when dealing with large and complex systems.
As far as results go, we achieved our goal of adding more headroom to one of the most critical pieces of Notion’s infrastructure. Our new CPU and IOPS utilization decreased dramatically, giving us plenty of headroom to grow into our new shard architecture. Interestingly, we found that distributing load across more machines reveals outliers in database consumption (i.e., some spaces in certain shards being responsible for an outsized impact on CPU is exaggerated in this world).

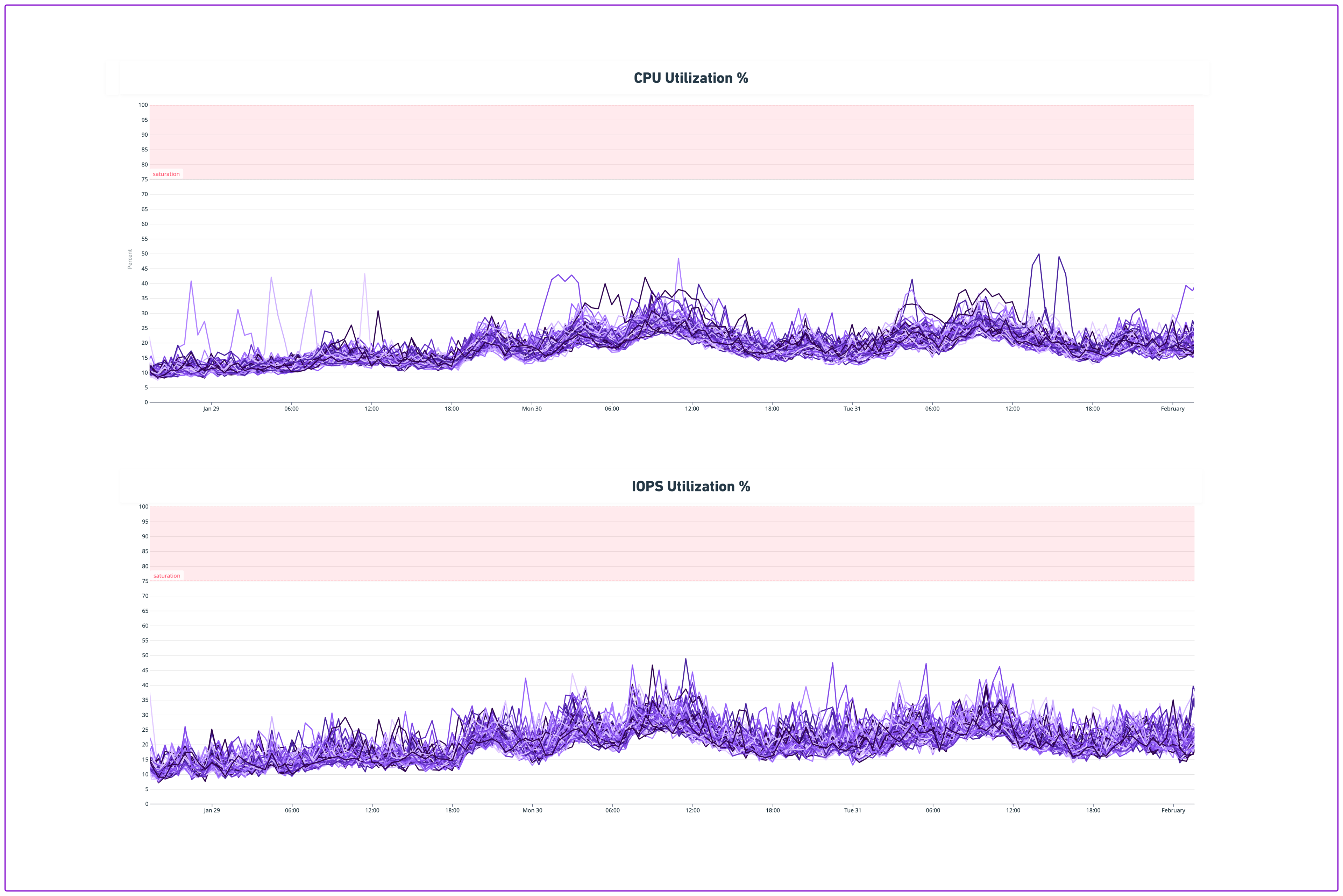
Overall, we’re proud of the work we’ve done and the improvements we’ve made to our database architecture. We’ll continue to monitor and improve our system to ensure that it can handle the growth and demand of our users.
Want to work together? Apply for our open roles here.