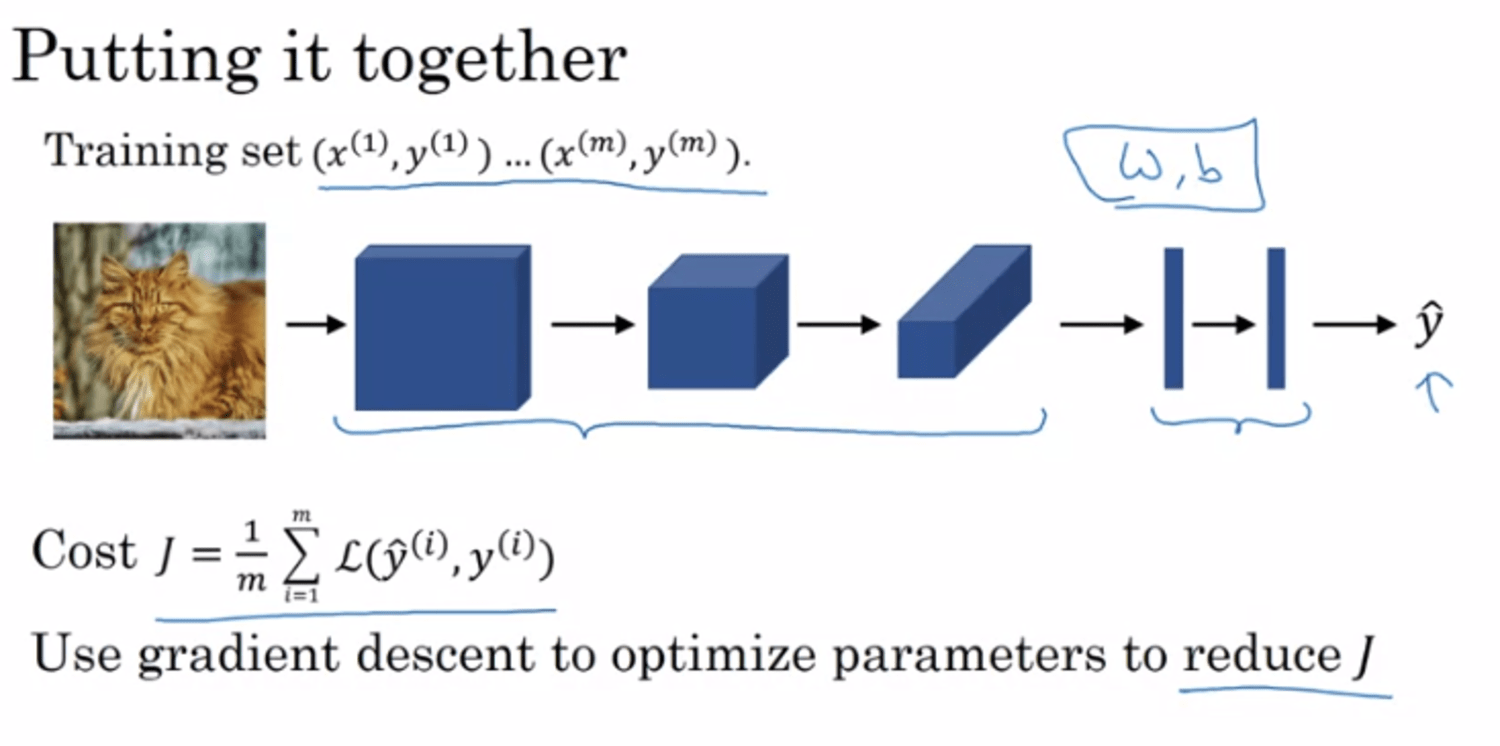
HxWxC → too large → too many params → need conv
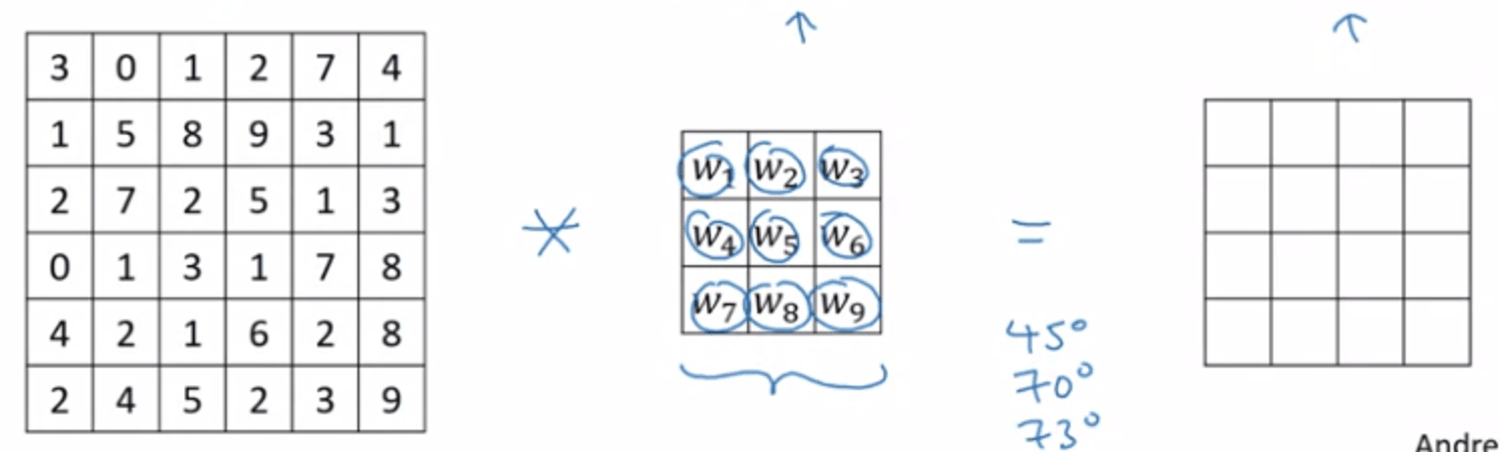
edge detection by a filter (3x3 for example) (or kernel) → multiply with original image by a convulution operator (*)
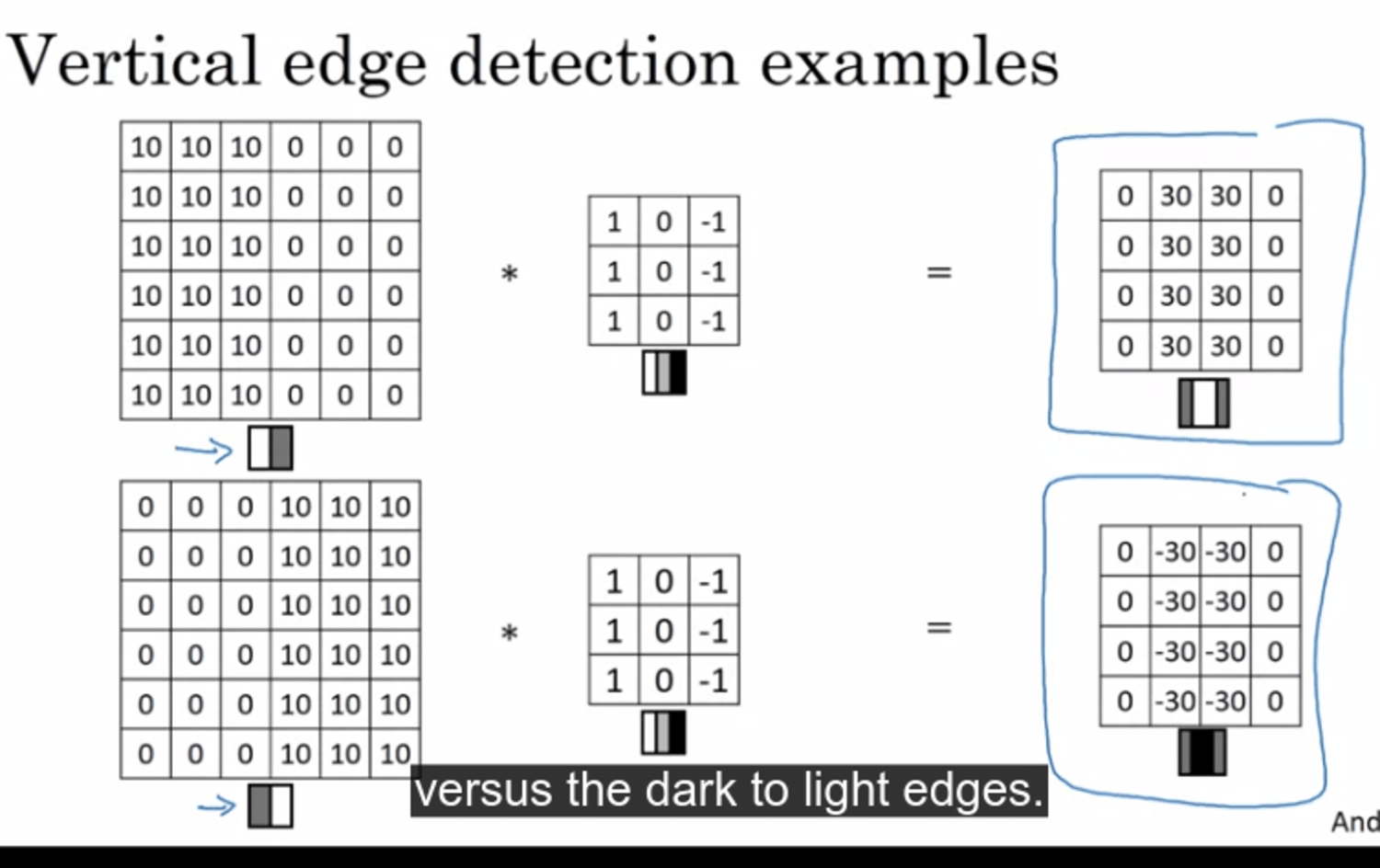
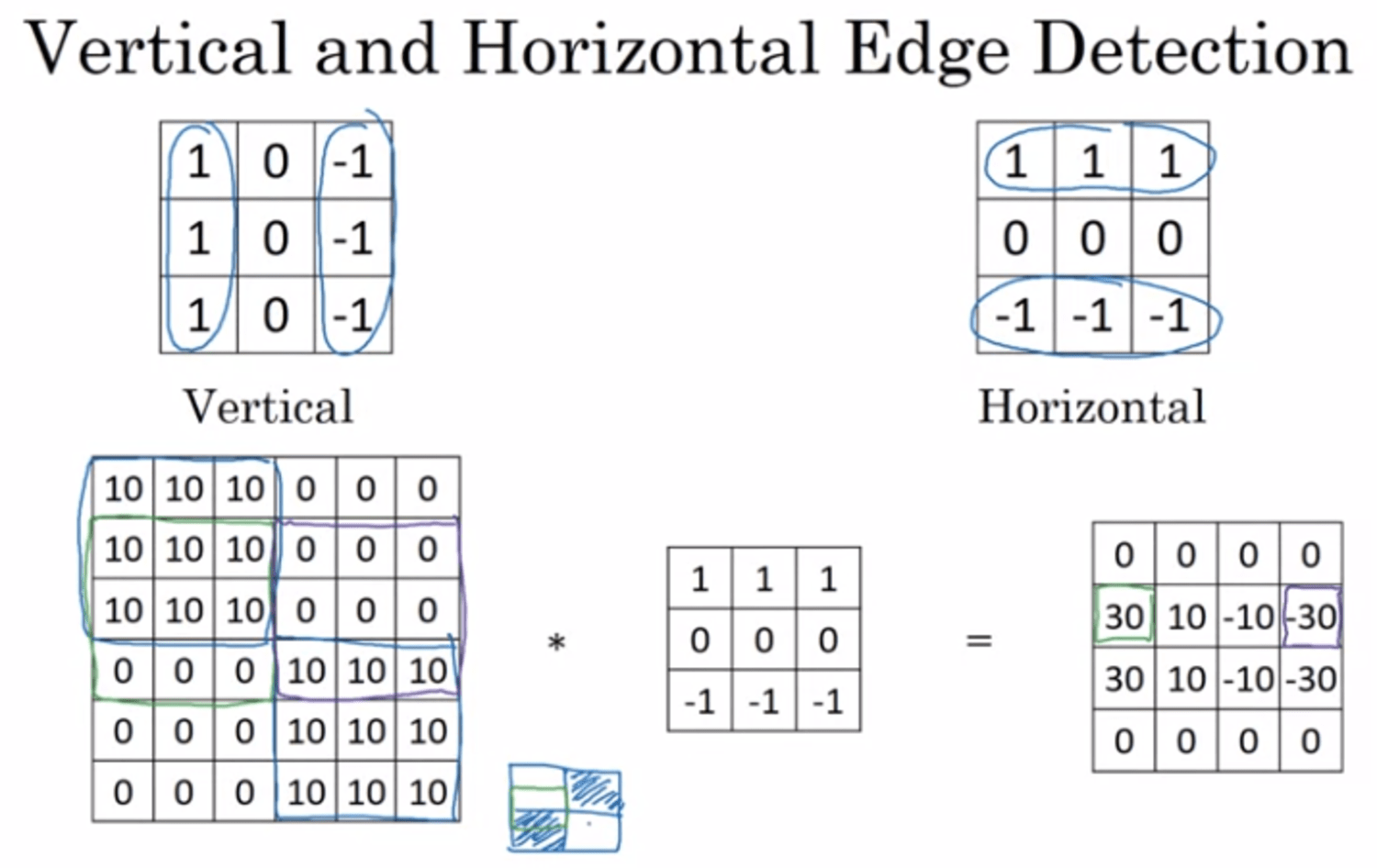
-
Sobel filter, Scharr filter (not only 0, 1, -1)
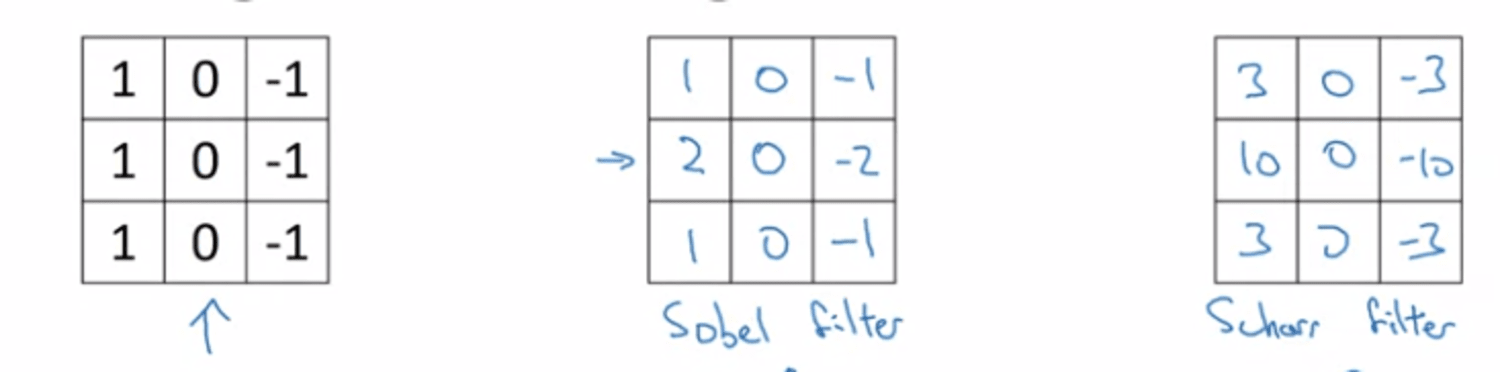
-
Can use backprop to learn the value of filter.
-
Not only edge, we can learn by degree of images.
Padding
- we don't want image to shrink everytime
- 6x6 * 3x3 (filter) → 4x4
- (nxn)*(fxf) → (n-f+1 x n-f+1)
- we don't want pixel on the corner or edges are used much less on the outputs
→ we can pad the images (mở rộng ra thêm all around the images): 6x6 → (pad 1) → 8x8
- 8x8 * 3x3 → 6x6 (instead of 4x4)
- → n+2p-f+1 x n+2p-f+!
- 2 common choices
- valid conv → no padding (nxn * fxf → n-f+1 x n-f+1)
- same conv → out's size = in's size → choose $p=\dfrac{f-1}{2}$
- f is usually odd → just convention
- 3x3, 5x5 are very common
Stride convulutions
- filter moves more than 1 step
- ex: 7x7 * 3x3 (with stride=2) → 3x3
- nxn * fxf → $(\dfrac{n+2p-f}{s}+1)\times (\dfrac{n+2p-f}{s}+1)$
- if fraction is not integer → round down → we take the
floor()
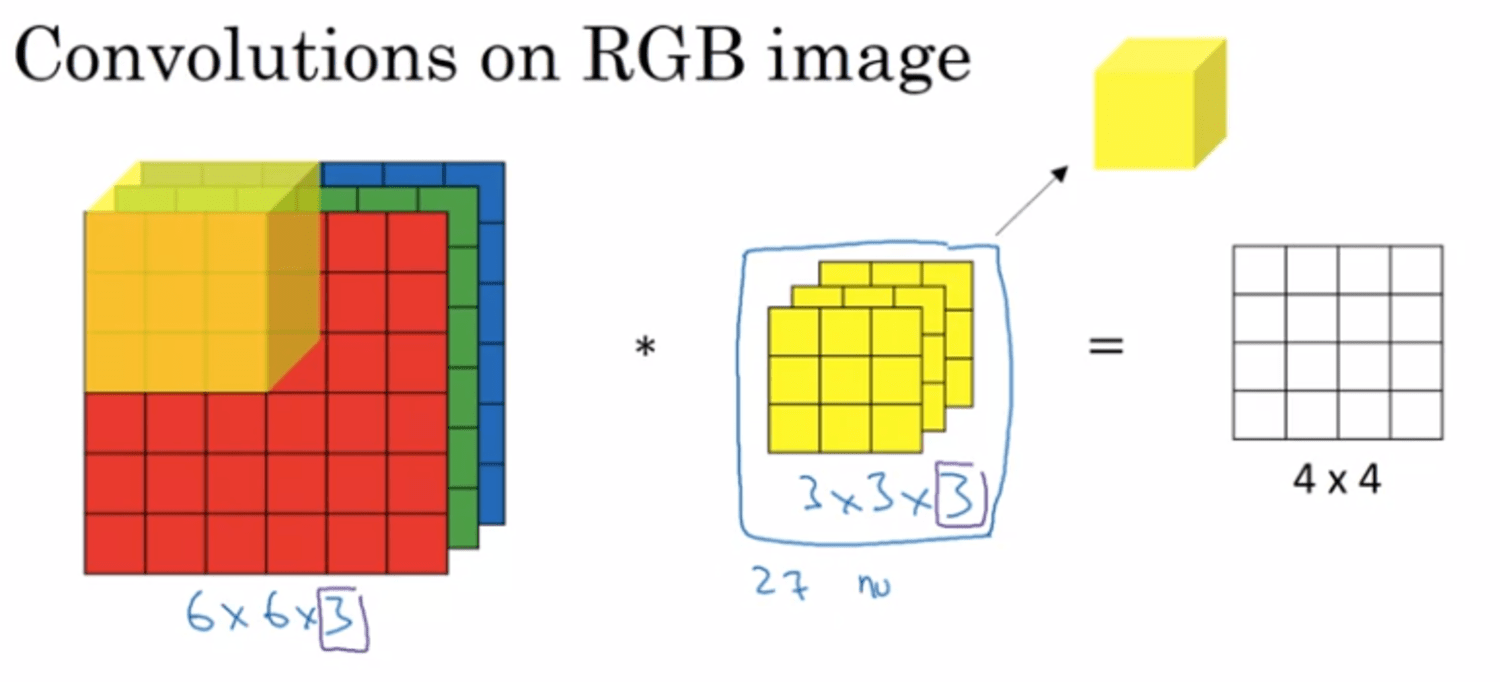
Conv over volumes (not just on 2d images) → ex on RGB images (3 channels)
-
6x6x3 * 3x3x3 (3 layers of filers) → 4x4x1
-
We multiply each layer together and then sum up all 3 layers → give only 1 number on the resulting matrix → that's why we only have 4x4x1
-
if we wanna detect verticle edge only on the red channel → 1st layer (in 3x3x3) can detect it, the other 2 is 0s.
-
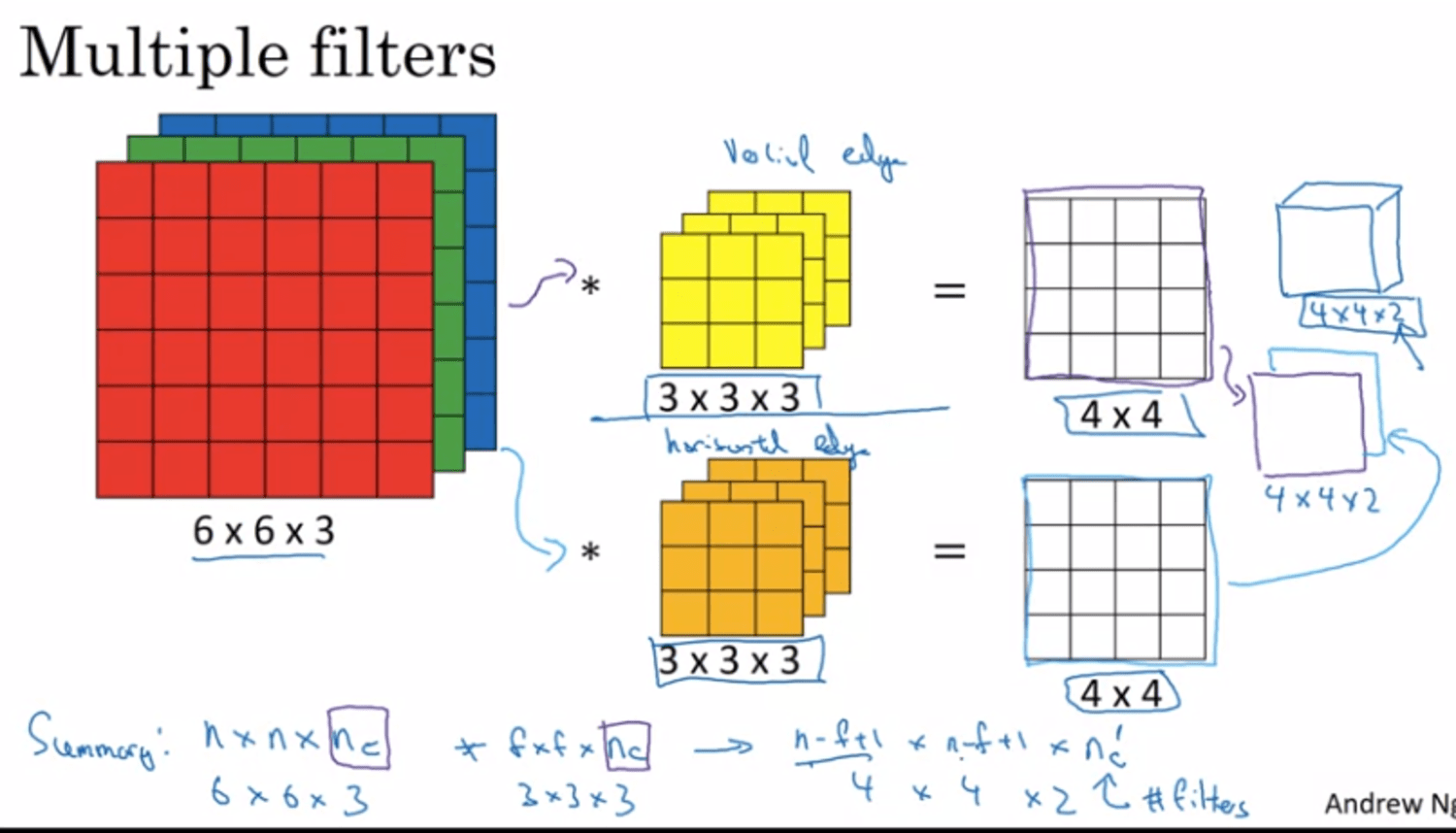
multiple filters at the same time? → 1st filter (verticle), 2nd (horizontal) → 4x4x2 (2 here is 2 filters)
-
we can use 100+ fileters → $n_c'=100+$
-
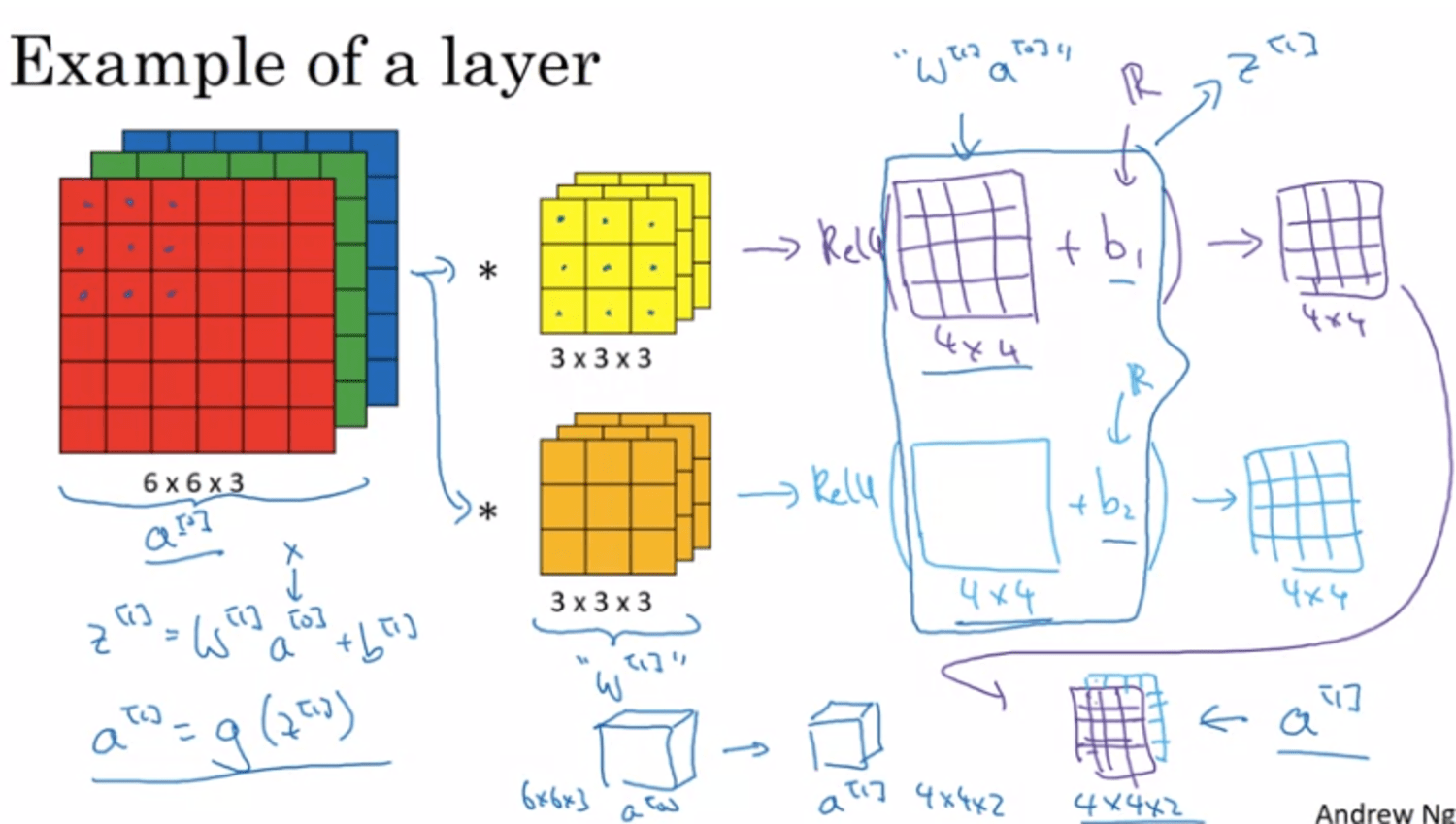
1 layer of ConvNet
-
if 10 filters (3x3x3) → how many parameters?
- each filter = 3x3x3=27 + 1 bias ⇒ 28 params
- 10 filters → 280 params
→ no matter what size of image, we only have 280 params with 10 filters (3x3x3)
-
Notations:

-
The number of filters used will be the number of channels in the output
SImple example of ConvNet

Type of layer in ConvNet
- Convolution (conv)
- Pooling (pool)
- Fully connected (FC)
Pooling layer
-
Purpose?
- to reduce the size of representation → speed up
- to make some of the features that detects a bit more robust
-
Max pooling → take the max of each region
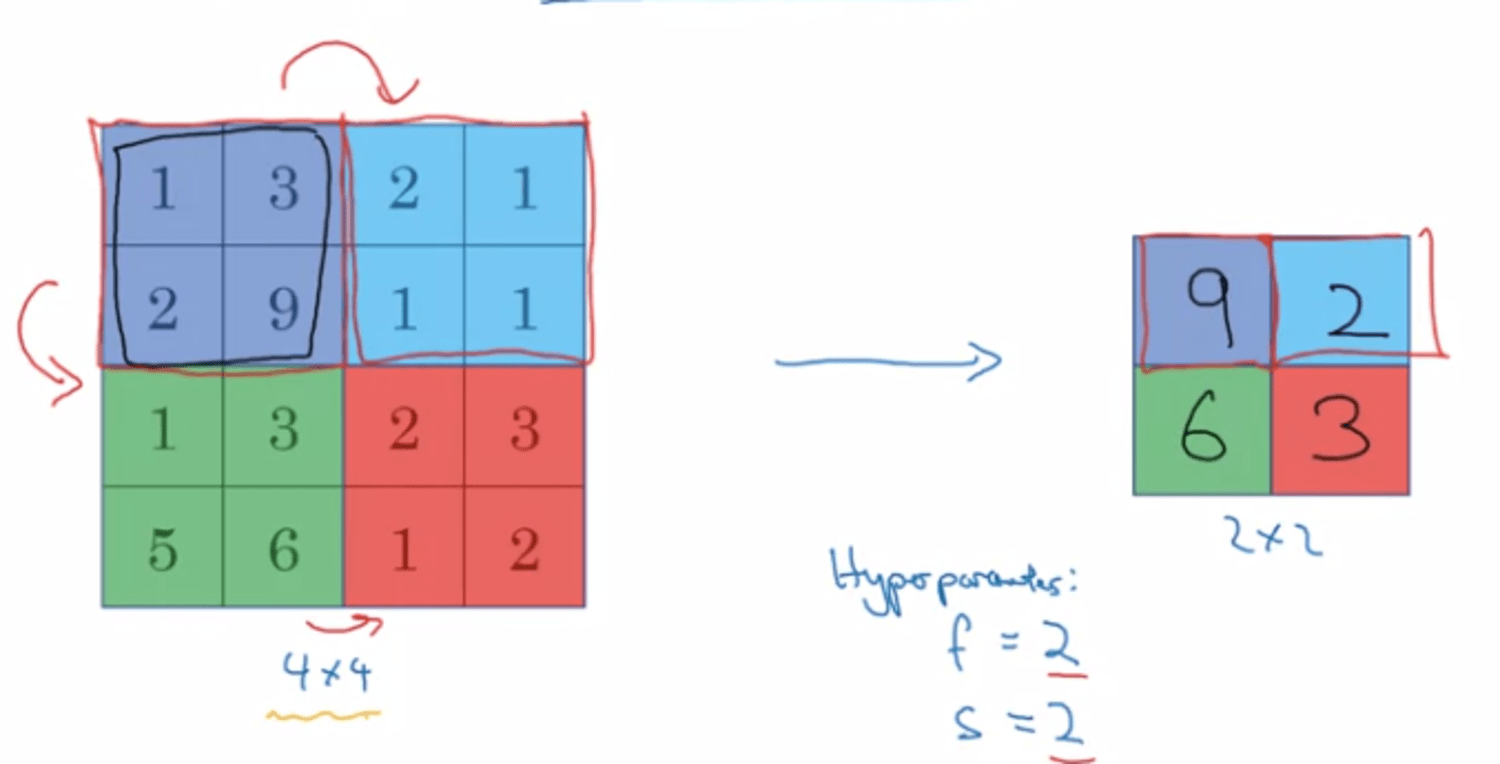
- Idea? if these features detected anywhere in this filter → keep the high number (upper left), if this feature not deteced (doesn't exist) (upper right), max is still quite small.
- Người ta dùng nhiều vì nó works well in convnet nhưng nhiều lúc ngta cũng ko biết meaning behind.
- Max pooling has no parameter to learn → grad desc doesn't change any thing.
- usually we don't need any padding! (p=0)
-
Average pooling → like max pool, we take average
→ max is used much more than avg
LeNet-5 (NN example) ← inspire by it, introduced by Yan LeCun
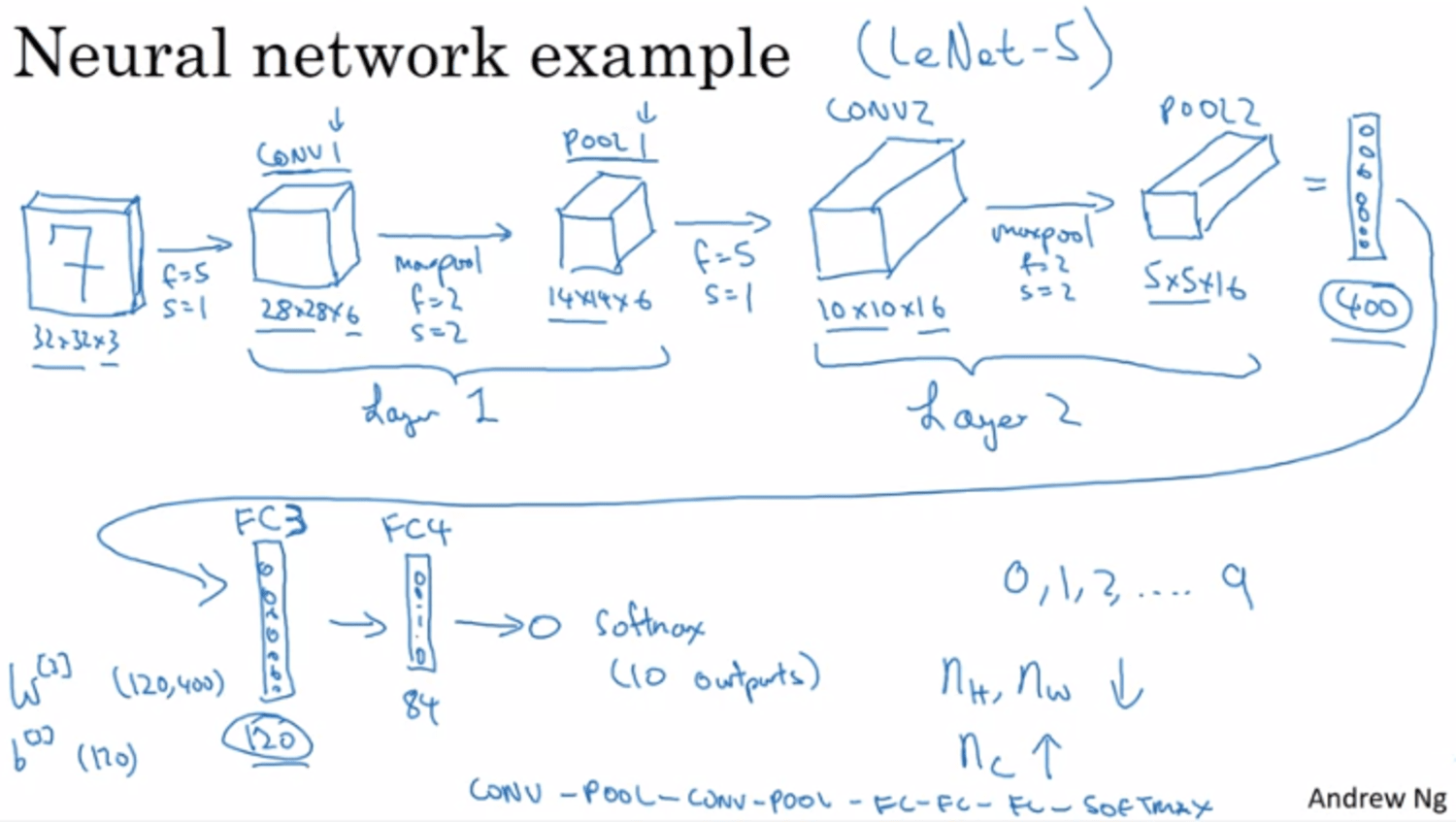
- Convention: 1 layer contains (conv + pool) → when people talk abt layer, they mean the layer with params to learn → pool doesn't have any param to learn.
- $n_H, n_W$ decrease, $n_C$ increase
- A typical NN looks something like that: conv → pool → conv → pool → ... → FC → FC → FC → softmax
- activation size go down
Why convolution?
- 2 main advantages of conv are: (if we use fully connected → too much parameters!!)
- parameter sharing: some feature is useful in one part of the image, it may be useful in another part.→ no need to learn different feat detected.
- Sparsity of connections: each layer, output value depends only on a small number of inputs.