
如何从零开始训练Stable Diffusion大模型? - 知乎
“Stable Diffusion大模型”一般指的是SD的基础模型,比如 SD V1.5、SD-XL 基础模型等等,这样的模型我们个人是没有这个实力去训练的,甚至任何一个小型公司都无力为之,那都至少是华为腾讯百度这种科技大厂,用百亿规模的训练集在动辄几百上千块最先进 GPU 上耗时几万个 GPU小时 训练出来的。所以,我猜你说的应该不是这种大模型,而是想说 SD 的微调模型。
目前 Stable diffusion 中用到的微调模型主要有四种,分别是 Textual Inversion (TI)以 Embeddings 为训练结果的模型、Hypernetwork 超网络模型、LoRA(包括 LoRA 的变体 LyCORIS)模型、Dreambooth 模型。
在国外网站上,有个视频博主 koiboi 用图形拓扑图来讲解了这四种 SD 模型的异同,并配有全程的视频讲解:koiboi 对四大SD模型的视频讲解。
下面我会先将这个视频用图文的方式讲解一下。然后再详细说明具体每一个模型的训练方式:
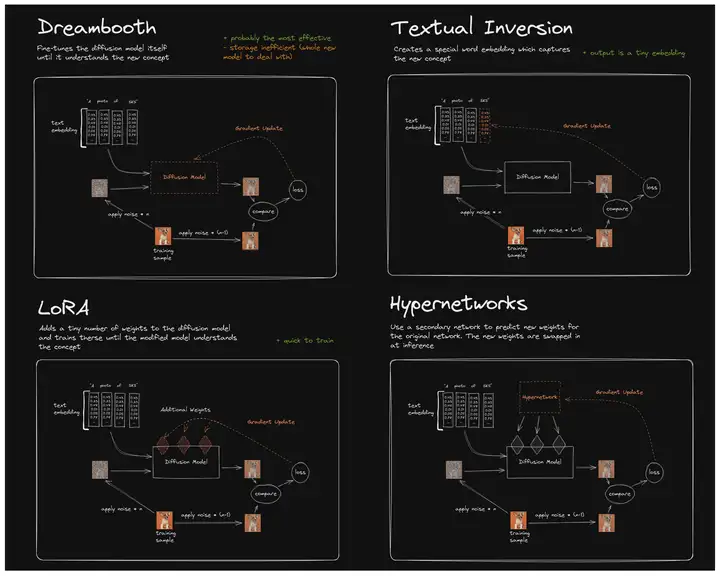
这个视频让非专业技术人员也可以对 SD 的四种微调模型的原理有一个基本的了解。虽然这并不算什么深入详细解刨的论文级别的讲解,但足够形象生动易懂。如果你还想更深入更地了解四种模型的细节可以先阅览每一种模型的详细介绍,分别在下面四篇文章链接中:
注:关于这四种模型的详细训练方法和参数等细节可以在各文章中查看对应的链接。
(有关Stable Diffusion的详细讲解,请查看此篇:Stable Diffusion 稳定扩散模型最详细解释)
以下是对 koiboi 视频中四个模型的简要介绍,看过简要介绍你便能了解到这些模型的基本构造和运作思路,然后就可以进一步查看各模型的训练详情,从而让你能从“0”基础起步筹划训练自己想要的模型了:
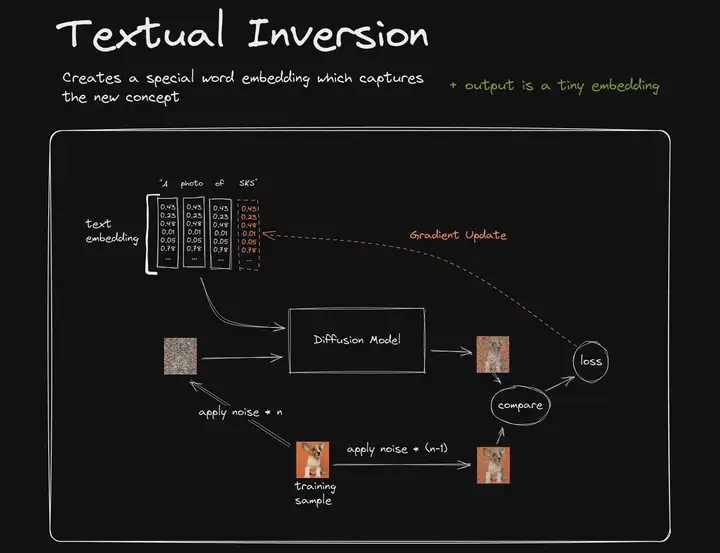
图1
首先看这样一个提示词:“A photo of SKS.”。