https://velog.io/@sj970806/MF-ALS란
수식이 깨져 보여서 수식 참고하려면 위 링크에서 보시면 편합니다.
Collaborative Filtering for Implicit Feedback Datasets 논문 내용 정리 + 관련 강의 내용 정리
1. Collaborative Filtering 기반 추천 시스템이란?
- 유저 A와 비슷한 취향을 가진 유저들이 선호하는 아이템을 추천아이템이 가진 속성을 사용하지 않으면서도 높은 추천 성능을 보임
Collaborative Filtering 분류
1.Neighborhood-based CF(Memory-based CF)
두가지 방법으로 분류 되며, 유저(아이템)간 유사도를 계산한 뒤, 타겟 유저(아이템)와 가장 높은 유사도를 지닌 유저(아이템)가 선호하는 아이템을 추천해준다.모든 유저(아이템)간 유사도를 구해야 하므로, 유저와 아이템의 개수가 증가 할 수록 연산량이 높아지는 단점이 있다.
2. Model-based CF
- 항목 간 유사성을 비교하는 것에서 벗어나, 데이터에 내재한 패턴을 이용하여 추천하는 CF 기법 (Parametric Machine Learning 을 사용한다)
- 잠재적 특성이나 패턴을 찾아내 추천에 이용하는 원리
- Non-parametric(KNN, SVD)
- Matrix Factorization
- Deep Learning
세가지 정도의 방법으로 분류 되며, Neighborhood-based CF의 단점들을 해결하기 위해 구상되었다.
NBCF의 단점, 한계1. Sparsity(희소성) 문제
- 데이터가 충분하지 않다면 추천 성능이 떨어진다. (유사도 계산이 부정확함)
- 데이터가 부족하거나 혹은 아예 없는 유저, 아이템의 경우 추천이 불가능하다. (Cold start)
2. Scalability(확장성) 문제
- 유저와 아이템이 늘어날수록 유사도 계산이 늘어난다.
- 유저, 아이템이 많아야 정확한 예측을 하지만 반대로 시간이 오래 걸린다.
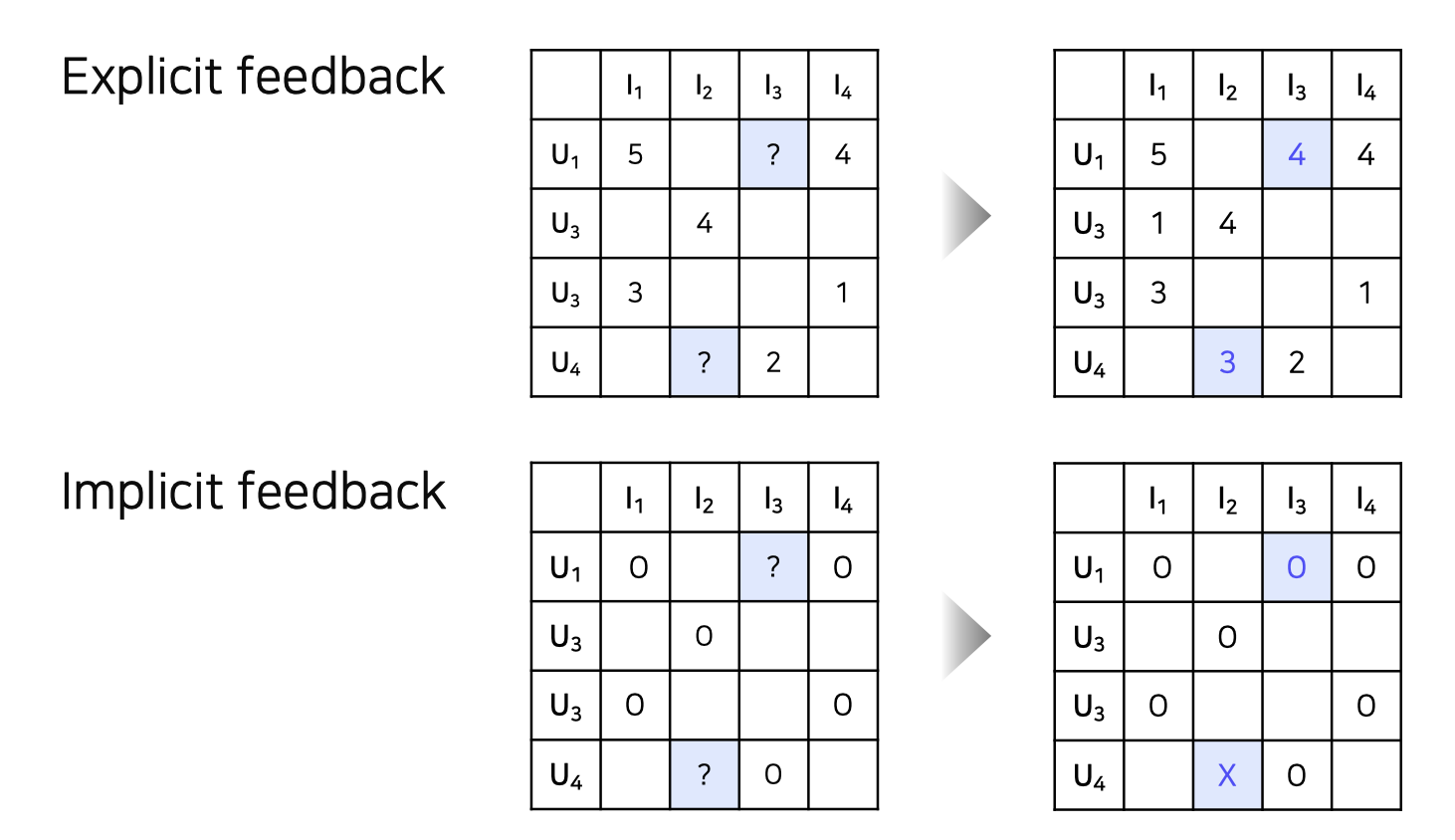
Explicit Data vs Implicit data
-
Explicit feedback영화 평점, 맛집 별점 등 item에 대한 user 의 선호도를 직접적으로 알 수 있는 데이터 지난 강의에서 다룬 문제는 Explicit feedback 문제
-
Implicit feedback클릭 여부, 시청 여부 등 item에 대한 user 의 선호도를 간접적으로 알 수 있는 데이터 유저-아이템 간 상호작용이 있었다면 1 (positive) 을 원소로 갖는 행렬로 표현 가능 현실에서는 implicit feedback 데이터의 크기가 훨씬 크고 많이 사용 됨
2. MF(Matrix Factorization)란?
- User-Item 행렬을 저차원의 User와 Item의 latent factor 행렬의 곱으로 분해하는 방법