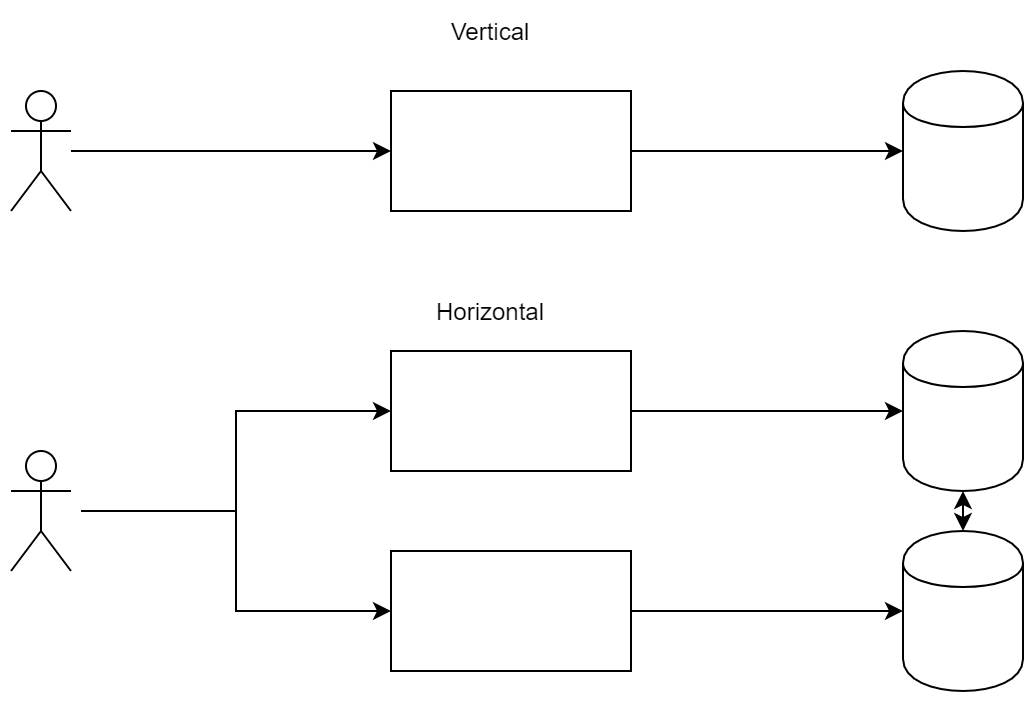
Самый простой и всем известный пункт. Условно, наиболее часто встречаются две схемы распределения нагрузки — горизонтальное и вертикальное масштабирования. В первом случае вы позволяете сервисам работать параллельно, тем самым распределяя нагрузку между ними. Во втором вы заказываете более мощные серверы или оптимизируете код.
Для примера я возьму абстрактное облачное хранилище файлов, то есть некоторый аналог OwnCloud, OneDrive и так далее.
Стандартная картинка подобной схемы ниже, однако она лишь демонстрирует сложность системы. Ведь нам необходимо как-то синхронизовать сервисы. Что будет, если с планшета пользователь сохранил файл, а потом хочет его посмотреть с телефона?
Разница между подходами: в вертикальном масштабировании мы готовы наращивать мощность узлов, а в горизонтальном — добавлять новые узлы, чтобы распределить нагрузку.
Command Query Responsibility Segregation довольно важный паттерн, так как он позволяет разным клиентам не только подключаться к разным сервисам, но и также получать одинаковые потоки событий. Его бонусы не столь очевидны для простого приложения, однако он крайне важен (и прост) для нагруженного сервиса. Его суть: входящие и исходящие потоки данных не должны пересекаться. То есть вы не можете отправить запрос и ожидать ответ, вместо этого вы отправляете запрос в сервис A, однако получаете ответ в сервисе Б.
Первый бонус этого подхода — возможность разрыва соединения (в широком смысла этого слова) в процессе выполнения долгого запроса. Для примера возьмем более-менее стандартную последовательность:
Представим, что в пункте 2 произошел обрыв связи (или сеть переподключилась, или пользователь перешёл на другую страницу, оборвав соединение). В этом случае серверу будет сложно отправить ответ пользователю с информацией, что именно обработалось. Применяя CQRS, последовательность будет немного иной: