Flink 中最核心的数据结构是 Stream,它代表一个运行在多个分区上的并行流。
在 Stream 上同样可以进行各种转换操作(Transformation)。与 Spark 的 RDD 不同的是,Stream 代表一个数据流而不是静态数据的集合。所以,它包含的数据是随着时间增长而变化的。而且 Stream 上的转换操作都是逐条进行的,即每当有新的数据进来,整个流程都会被执行并更新结果。这样的基本处理模式决定了 Flink 会比 Spark Streaming 有更低的流处理延迟性。
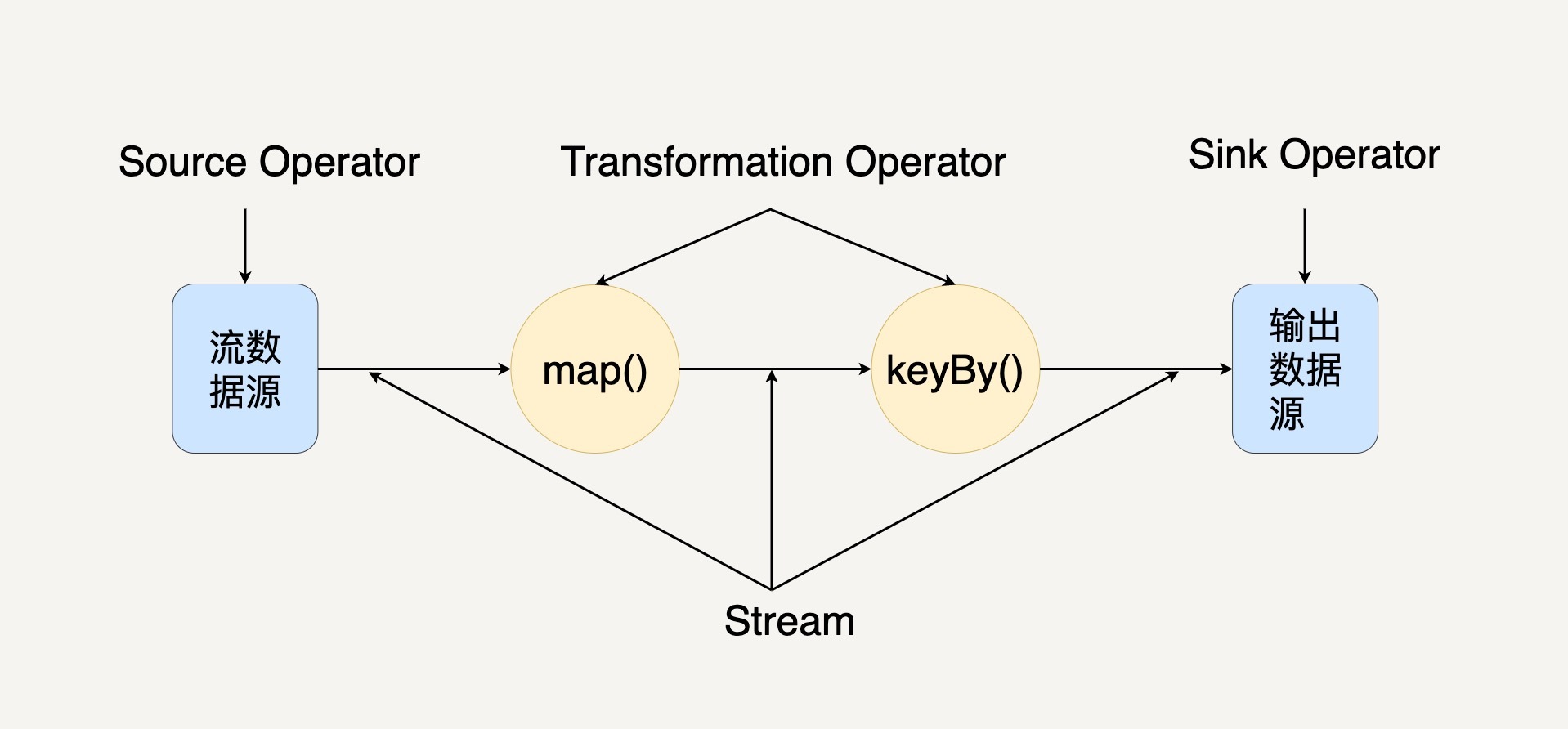
当一个 Flink 程序被执行的时候,它会被映射为 Streaming Dataflow,下图就是一个 Streaming Dataflow 的示意图。
在图中,你可以看出 Streaming Dataflow 包括 Stream 和 Operator(操作符)。转换操作符把一个或多个 Stream 转换成多个 Stream。每个 Dataflow 都有一个输入数据源(Source)和输出数据源(Sink)。与 Spark 的 RDD 转换图类似,Streaming Dataflow 也会被组合成一个有向无环图去执行。
在 Flink 中,程序天生是并行和分布式的。一个 Stream 可以包含多个分区(Stream Partitions),一个操作符可以被分成多个操作符子任务,每一个子任务是在不同的线程或者不同的机器节点中独立执行的。如下图所示:
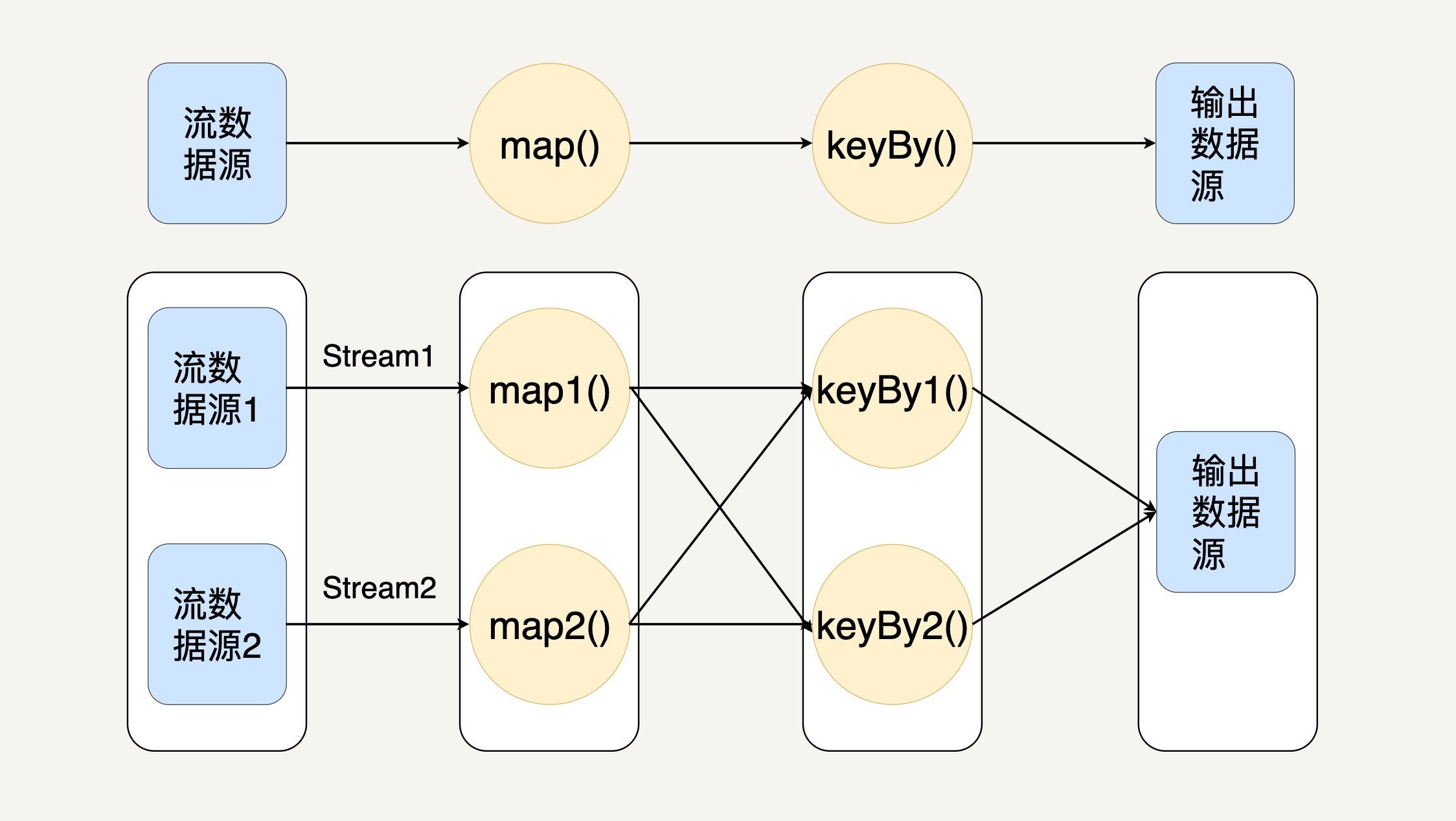
从上图你可以看出,Stream 在操作符之间传输数据的形式有两种:一对一和重新分布。