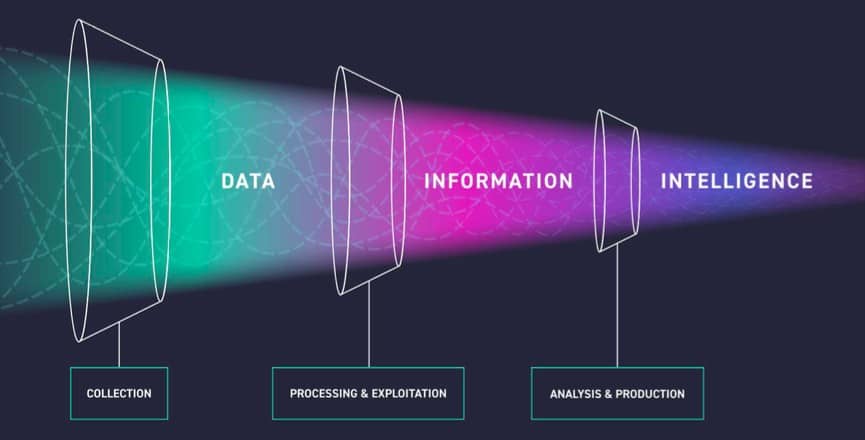
As explained in the previous section, the data collected for threat intelligence will be complex and very large, as we captured the data from multiple sources. If it is not processed properly, it will lead to many false positives and prevent us from producing quality threat intelligence. Therefore, we need to understand the data and interpret it properly. In this section, we will cover the cause and effect relationship that will be useful for us when we interpret the data rather than diving into the "Big Data Analysis" etc. as it is out of scope. Those who are curious about "Big Data Analysis" can easily find information about it online.
When analyzing data collected for threat intelligence, it is very important to weed out false data to avoid false positive situations. For example, if the hash belonging to one of Microsoft's legit applications is accidentally included in the intelligence data, this application will be marked as malicious within the organization. This will cause disruption of the processes that need to be done with that application within the organization. For this reason, we need to convert all the legitimate data such as IP addresses, hashes, domains, and URLs into a whitelist, apply it to filter, and clean and legitimate data of the intelligence. Regardless of the field, the data collected should be cleaned from false information. Before this process, we have to classify and label the complex structure to be able to navigate through the data faster and interpret it more easily. We can constantly be aware of threats through the bridge between the attack surface and the data by associating each classified data group with the relevant parts of our attack surface.
What is the first data collected in threat intelligence called?
Big Data