Time: UTC+8 2025/10/20 12:30-13:30
I found him on Zhihu.com, where he shared his experience in oneDNN Graph Compiler project. At that time he is an Engineer in Intel Shanghai. In Zhihu he introduced how to use their compiler, their experience, and bottleneck. We found similar experience like "too many barriers", "thread load imbalance" in serving LLM in CPU. So I just send him an invitation, and add his WeChat. He likes my blogs "Matmul in C/Java, a comparsion". (I should post more!)
I didn’t record the meeting, but I remember 95% of the content in the meeting. The chat was in Chinese, and I just translated our talking in my own words.
Haibin: Hello senpai ! Very happy to know you! May you introduce what did you do on CPU Graph Compiler?
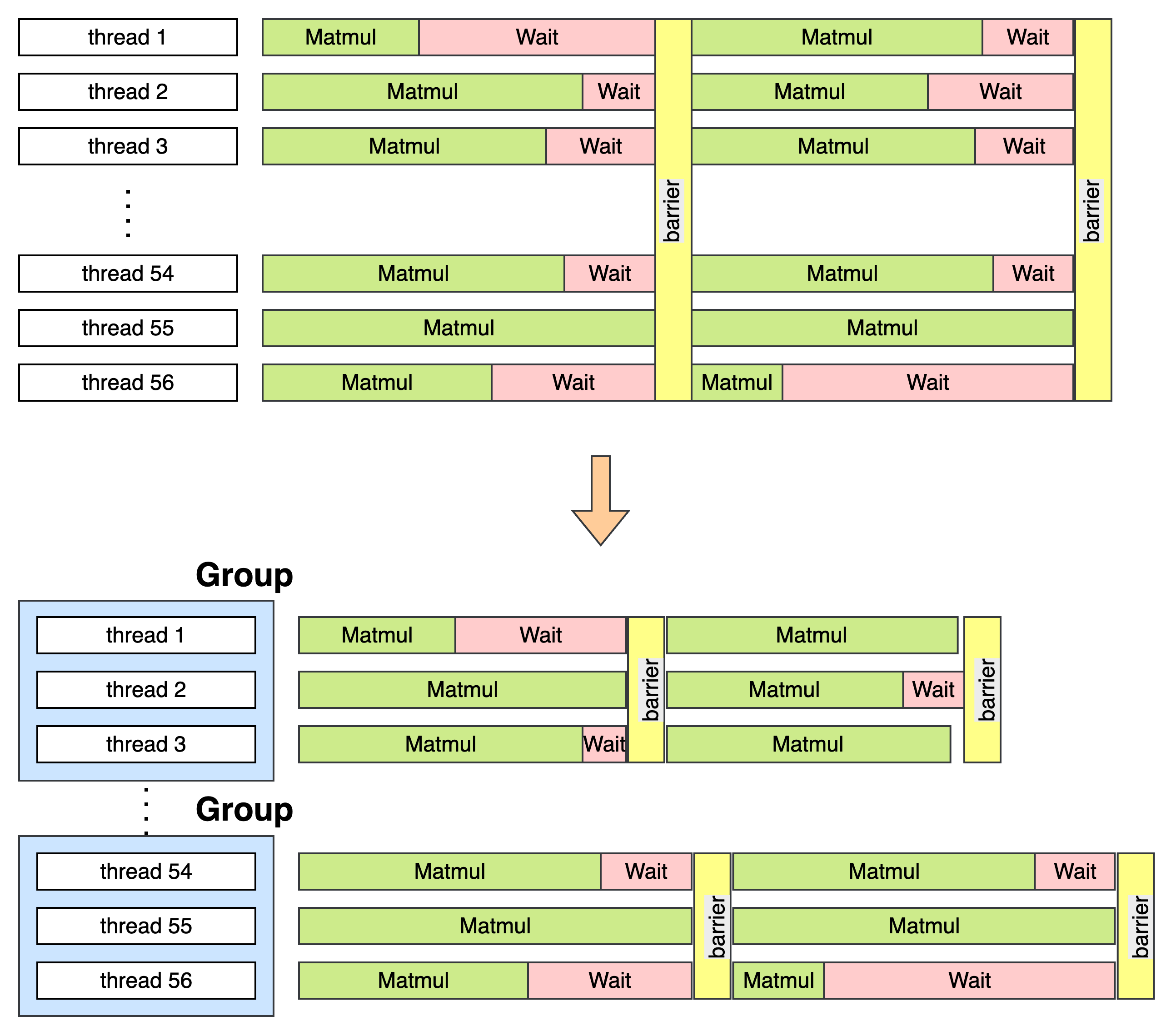
Senpai: Yeah very happy to chat with you too. So we built a CPU Graph Compiler for AI Models. Basically the compiler will accept a kind of IR from oneDNN (Somehow for political issues, we didn't use MLIR), then it generates high performance kernels for the models. In generation phases, we introduced several optimizations. For example, grouping the barriers, better AMX instructions kernels.
Now let me introduced these optimizations:
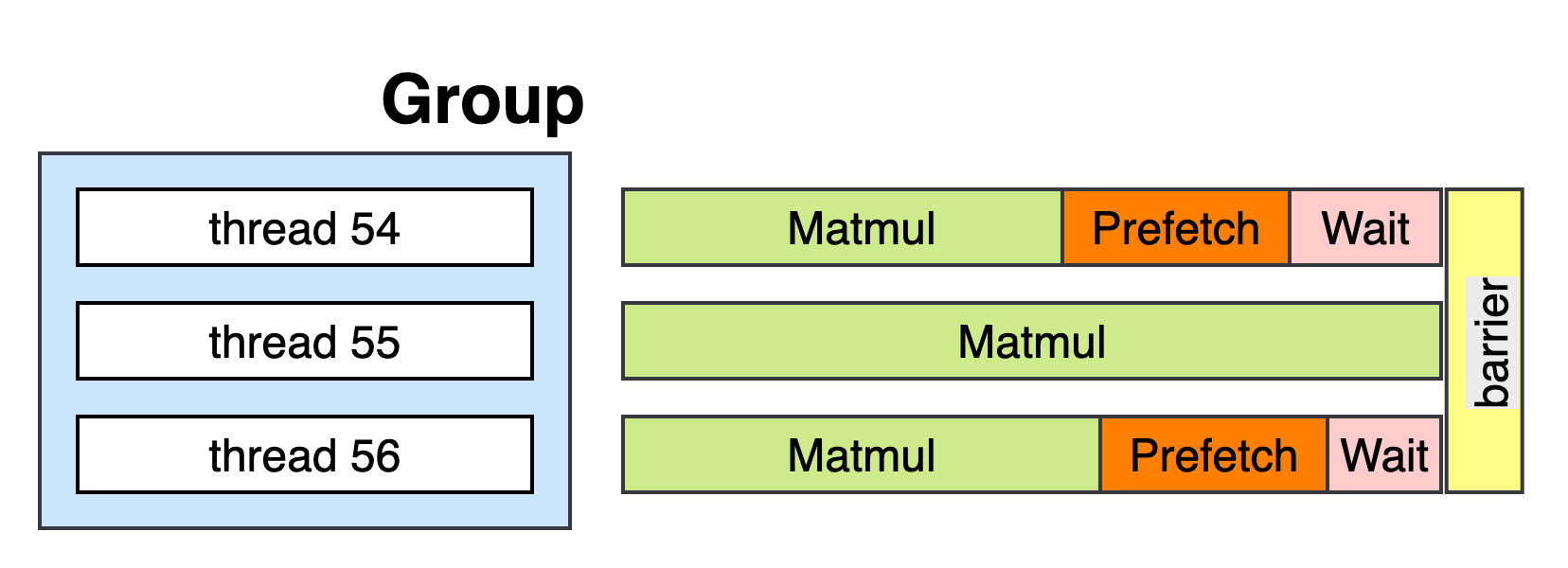
barrier using spinlock. This is because spinlock is more lightweight. And we also use atmoic instructions. The main backend like tbb or openmp's jobs are only for opening up the multi-threads.M and N dimensions, while we found that spilt the K dimension sometimes works better. But it will be more complicated since K axis needs reductions. So maybe for your llama.cpp, is it good enough for a good matmul kernel? (Me: no they are not the best)