1. 프로젝트 개요
대회에서는 implicit feedback 기반의 sequential recommendation 시나리오를 바탕으로 사용자의 time-ordred sequence에서
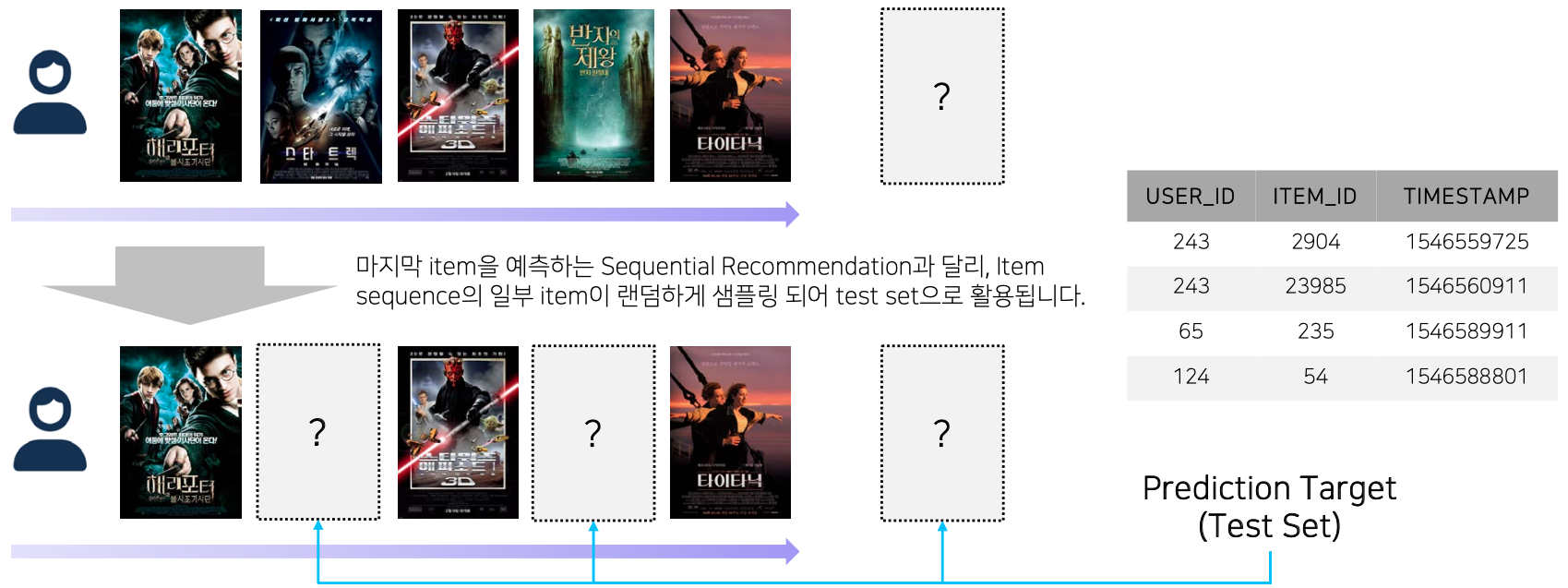
일부 item이 누락된 (dropout)된 상황을 상정하기 때문에, 마지막 아이템 예측 뿐만아니라 중간 아이템 또한 예측해야 한다.
1-1. 프로젝트 소개
-
본 프로젝트는 Movie Recommendation, 즉 유저의 영화 시청 이력 데이터를 바탕으로 유저에게 볼 영화를 추천해주는 대회에서 솔루션을 제시한다.
-
Timestamp 정보가 들어간 implicit feedback 데이터를 통해 모든 유저에게 10개의 영화를 추천하여 추천 리스트의 정확성을 평가한다.
-
평가를 위한 정답(ground-truth) 데이터는 sequential recommendation 시나리오를 바탕으로 하는 동시에
복잡한 실제 상황을 가정하여 다음과 같이 원본 데이터에서 추출되었다.
- 특정 시점을 기준으로 이후의 데이터를 전부 추출
- 특정 시점을 기준으로 이전의 데이터 중 랜덤하게 추출
-
위와 같이 데이터셋이 구성되어 있기 때문에, 단순 sequential한 예측에 최적화된 모델은 static 데이터의 예측에 약점을 보일 수 있고,
반대로 static한 예측에 최적화된 모델은 sequential한 예측에 약점을 보일 수 있다.
1-2. 데이터 요약
- 본 대회는 추천시스템 연구 및 학습 용도로 가장 널리 사용되는 MovieLens 데이터를 implicit feedback의 형식으로 수정하여 사용한다.
- input
- 유저와 아이템의 상호작용 데이터 5,154,471개
- 아이템의 메타 데이터
- 장르, 제목, 개봉년도, 감독, 작가
- 장르와 제목을 제외하고 아이템의 메타 데이터에는 결측이 존재한다.
- 유저는 총 31360명이며, 아이템은 총 6807개이다.
- 유저와 아이템의 번호가 0 ~ 1에서 시작해 arange 되어있지 않았기에, 라벨인코딩 후 진행하였다.
- output
- 유저 각 31360명에 대해 10개의 아이템을 추천하여 313600 행의 user, item 컬럼을 가진 csv 파일을 제출한다.
1-3. 평가 지표

- Recall@10 - 각 유저에 대해 10개의 영화를 추천하고, 이는 각 유저의 Recall 지표에 대한 평균을 통해 평가된다.
- 통상적인 Recall 지표는 유저가 관심 있는 모든 아이템 중에서 모델이 추천한 아이템 k개가 얼마나 포함되는지의 비율을 의미한다.