In this post, we'll implement a GPT from scratch in just 60 lines of numpy. We'll then load the trained GPT-2 model weights released by OpenAI into our implementation and generate some text.
Note:
This post assumes familiarity with Python, NumPy, and some basic experience training neural networks.
This implementation is missing tons of features on purpose to keep it as simple as possible while remaining complete. The goal is to provide a simple yet complete technical introduction to the GPT as an educational tool.
The GPT architecture is just one small part of what makes LLMs what they are today..
All the code for this blog post can be found at github.com/jaymody/picoGPT.
EDIT (Feb 9th, 2023): Added a "What's Next" section and updated the intro with some notes.EDIT (Feb 28th, 2023): Added some additional sections to "What's Next".
GPT stands for Generative Pre-trained Transformer. It's a type of neural network architecture based on the Transformer. Jay Alammar's How GPT3 Works is an excellent introduction to GPTs at a high level, but here's the tl;dr:
Large Language Models (LLMs) like OpenAI's GPT-3, Google's LaMDA, and Cohere's Command XLarge are just GPTs under the hood. What makes them special is they happen to be 1) very big (billions of parameters) and 2) trained on lots of data (hundreds of gigabytes of text).
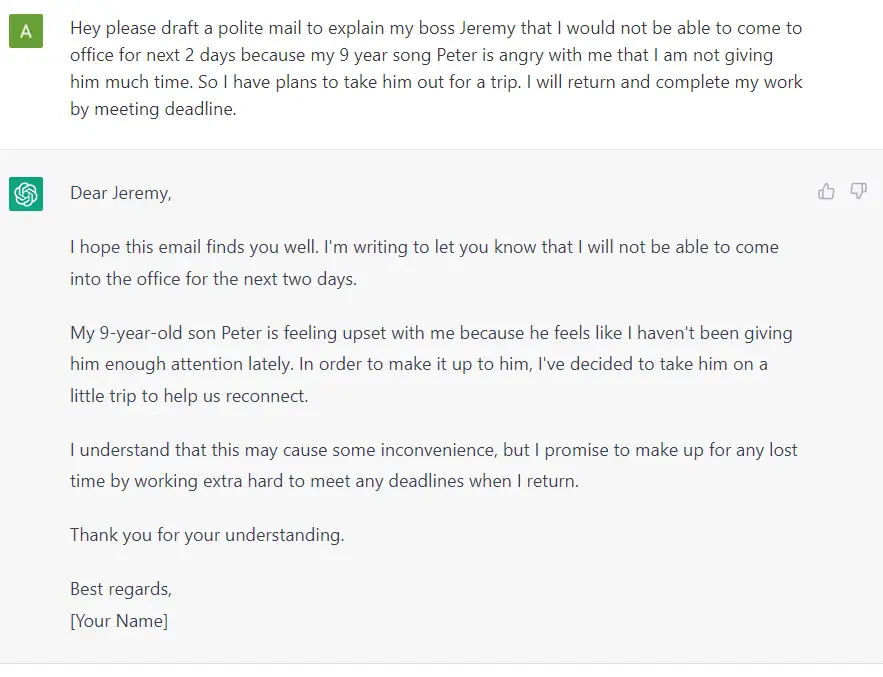
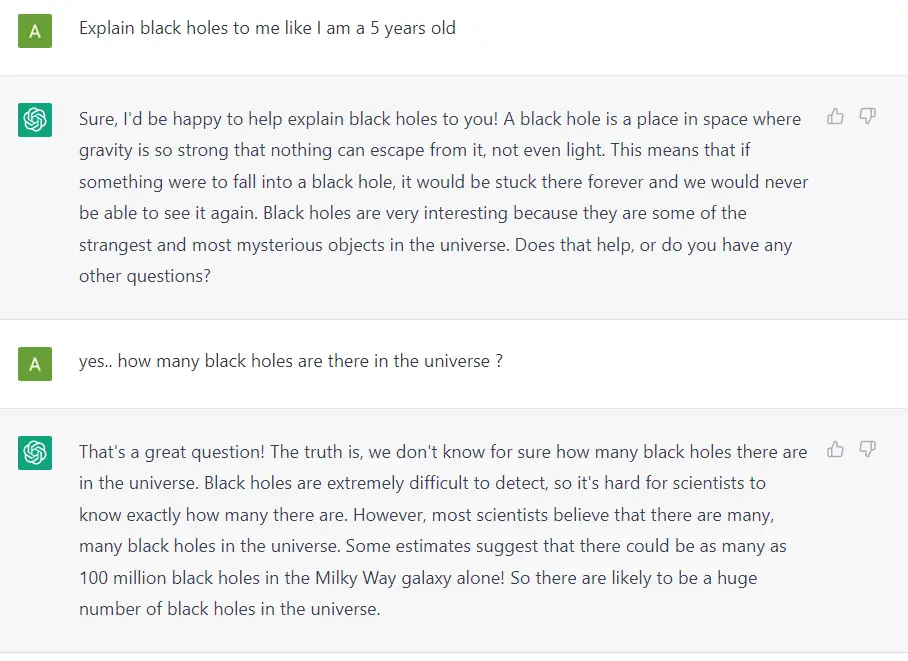
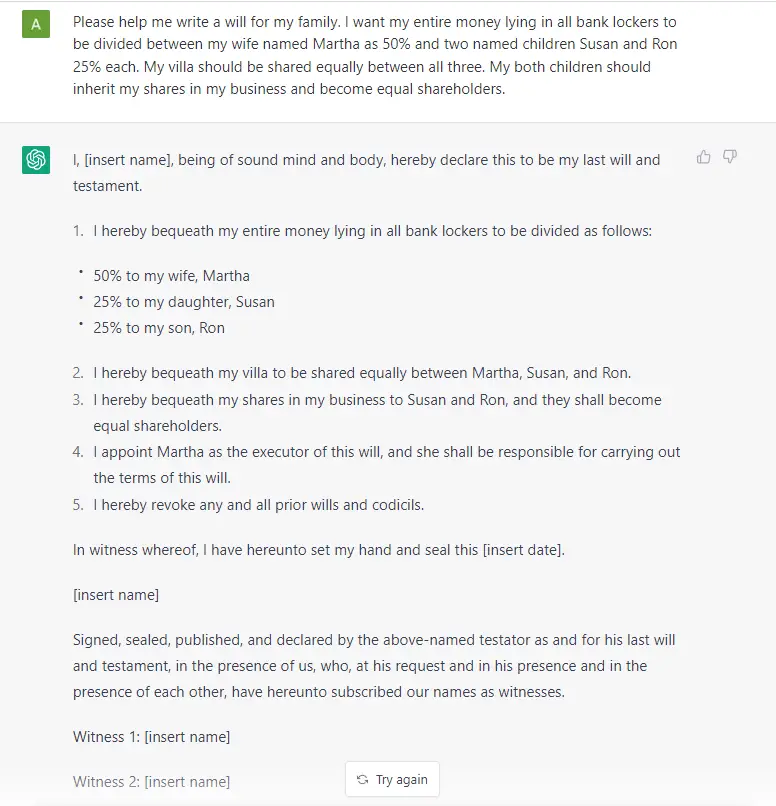
Fundamentally, a GPT generates text given a prompt. Even with this very simple API (input = text, output = text), a well-trained GPT can do some pretty awesome stuff like write your emails, summarize a book, give you instagram caption ideas, explain black holes to a 5 year old, code in SQL, and even write your will.
So that's a high-level overview of GPTs and their capabilities. Let's dig into some more specifics.
The function signature for a GPT looks roughly like this:
def gpt(inputs: list[int]) -> list[list[float]]:
# inputs has shape [n_seq]
# output has shape [n_seq, n_vocab]
output = # beep boop neural network magic
return output
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}