Finetuning
The process of adapting a pre-trained large language model (LLM) to a specific task or dataset by continuing its training on a smaller, specialized dataset.
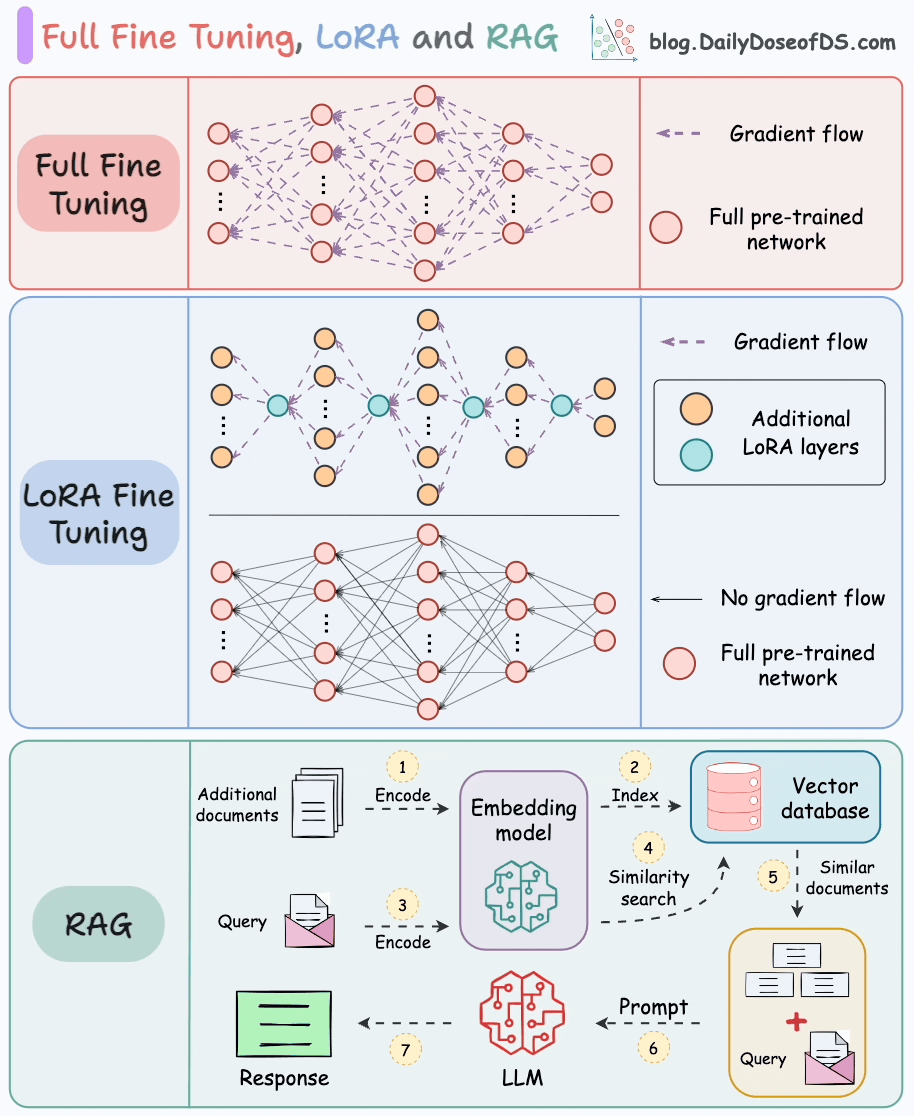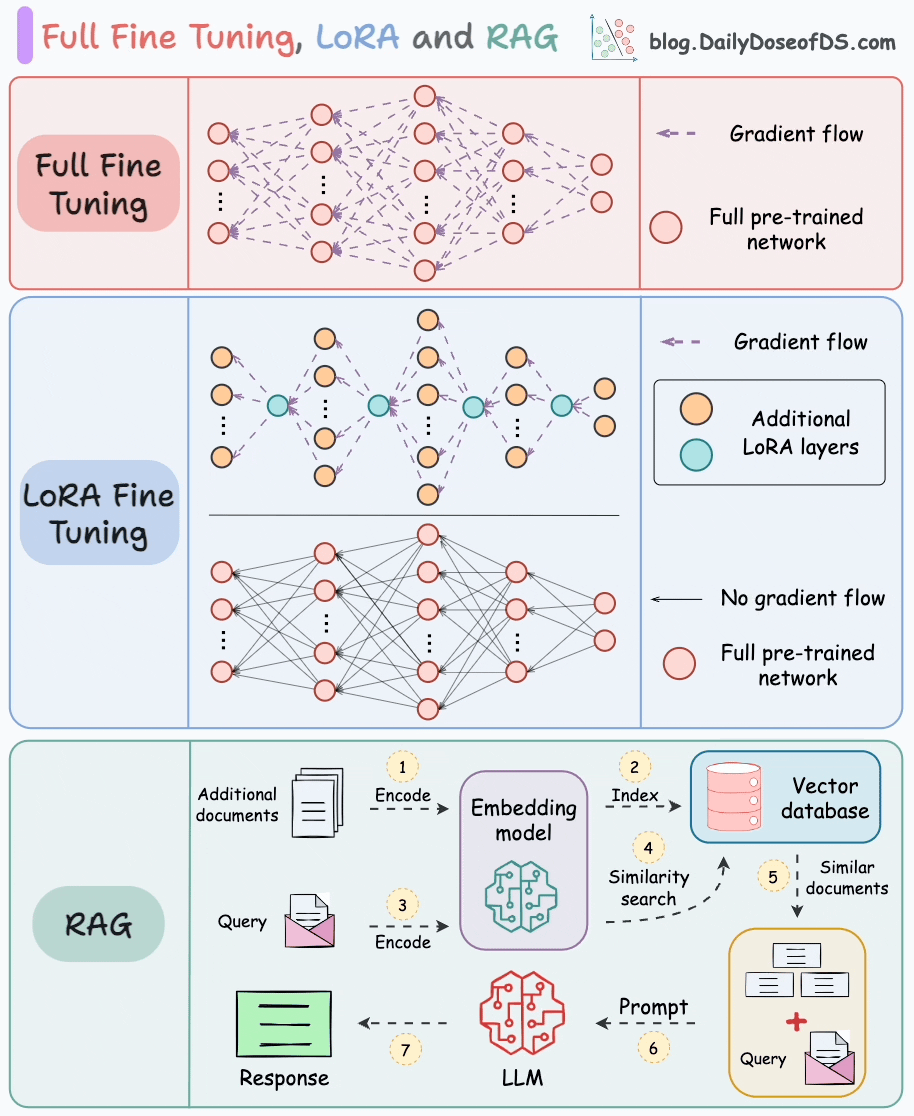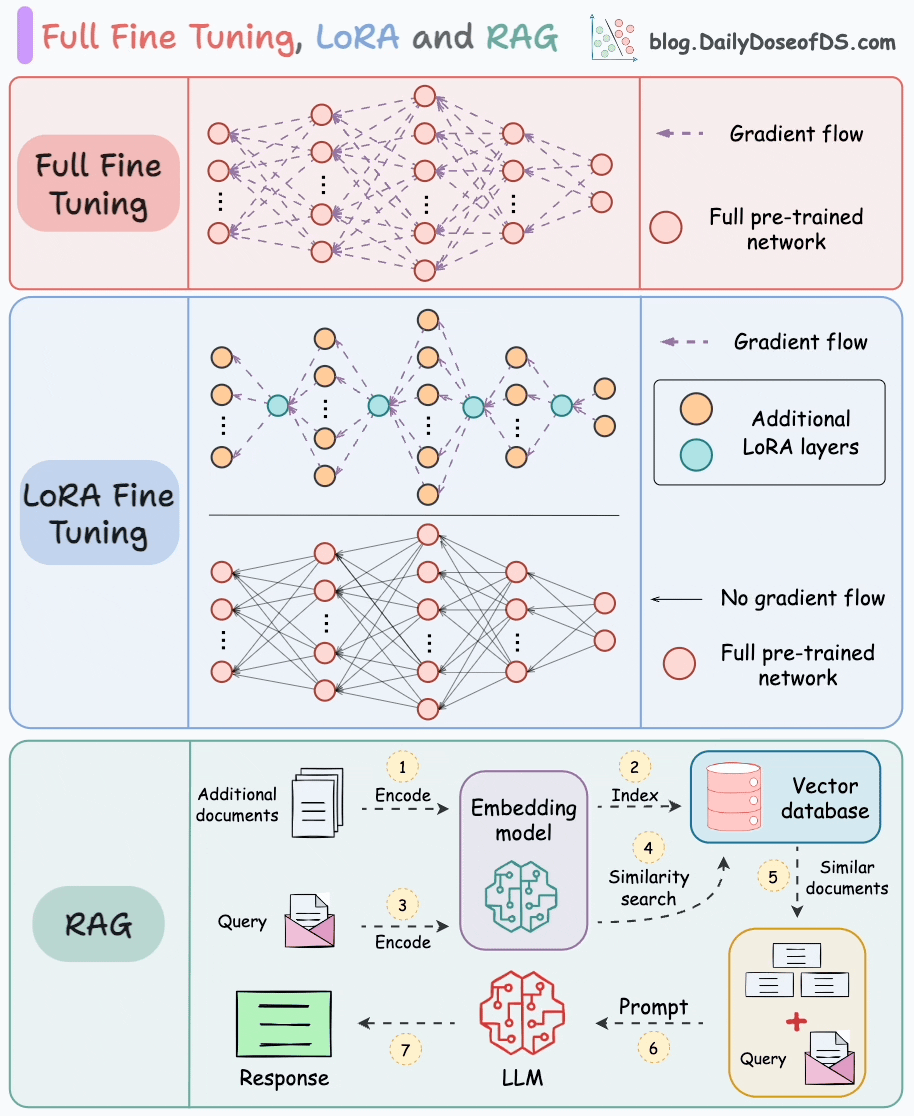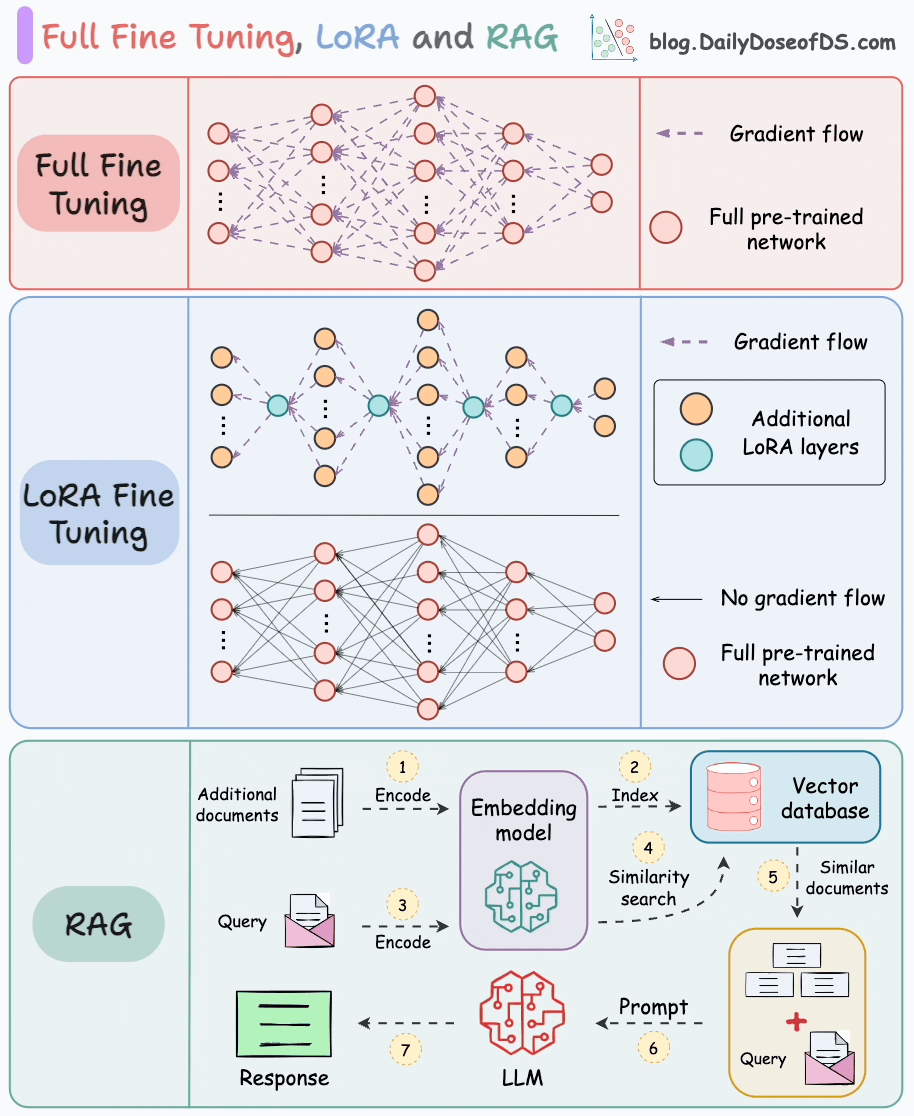
Parameter-Efficient Fine-Tuning (PEFT)
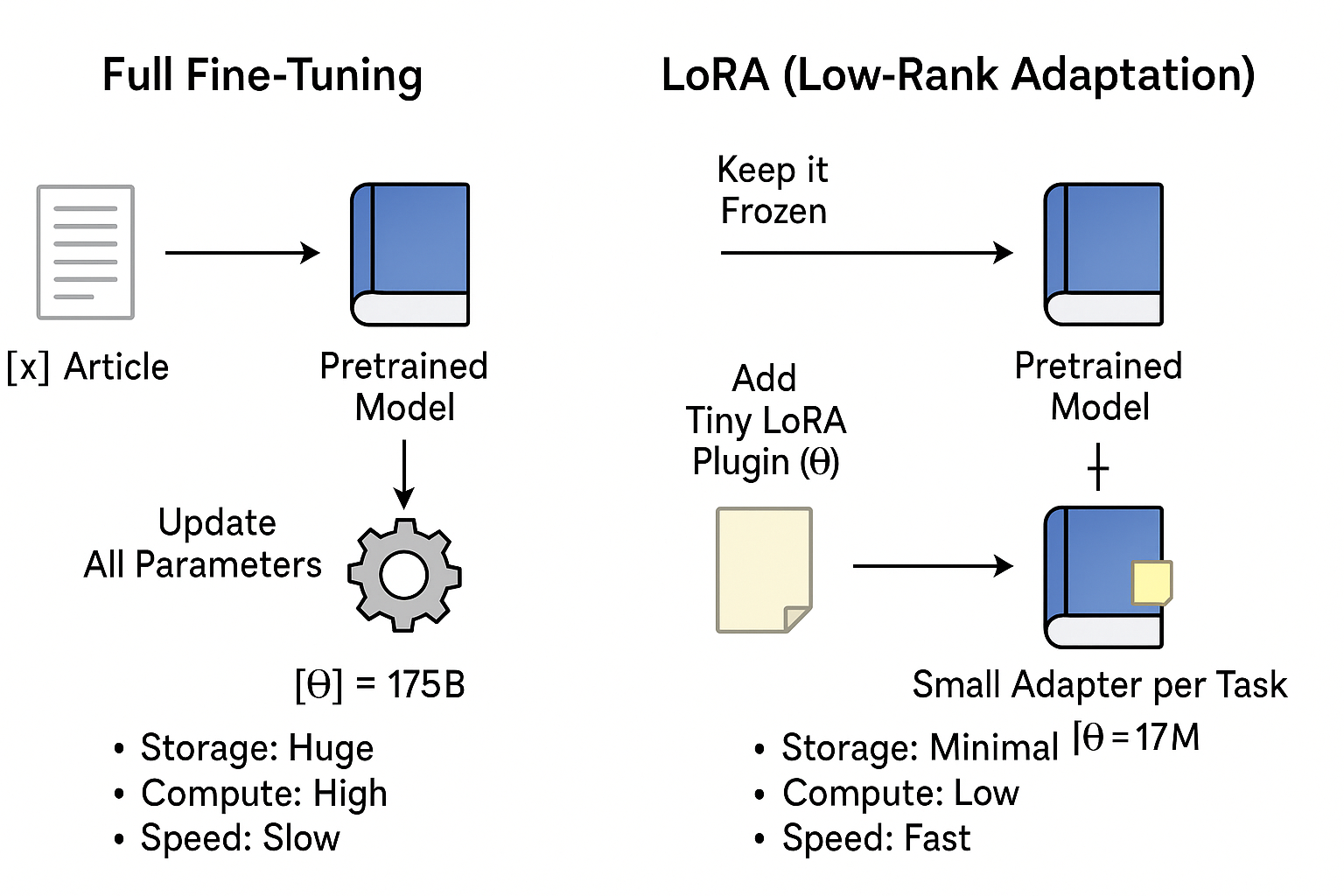
- **Low-Rank Adaptation (**LoRA)
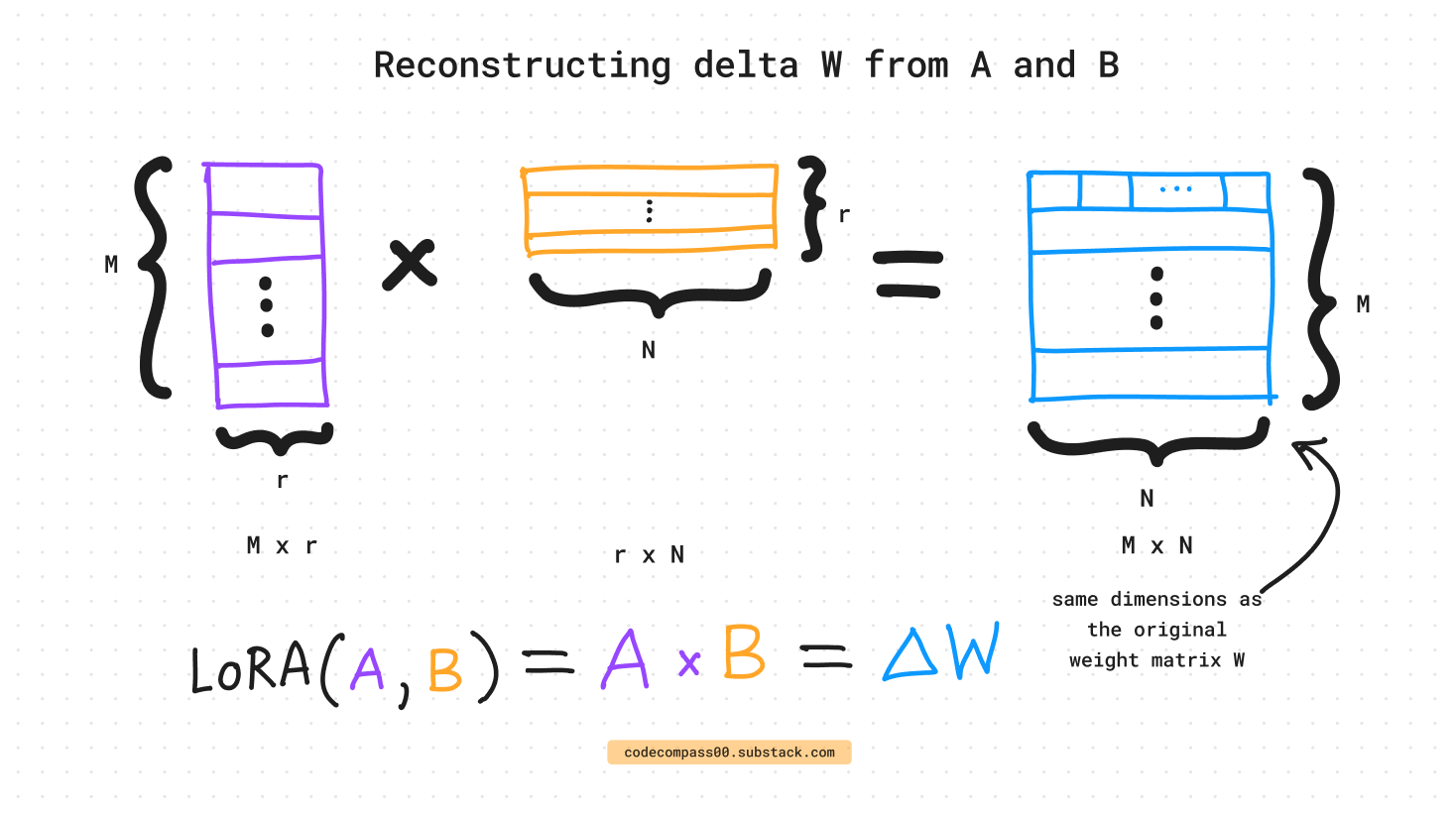
- The key innovation lies in decomposing the weight change matrix ∆W into two low-rank matrices, A and B.
- “Low-rank” adaptation matrices: The smaller sample size of parameters to be trained and merged into “frozen” base model
- They are called low-rank because they are matrices with a low number of parameters and weights.
- Instead of directly training the parameters in ∆W, LoRA focuses on training the parameters in A and B matrixes and combine them with the original parameters to act as one single matrix.
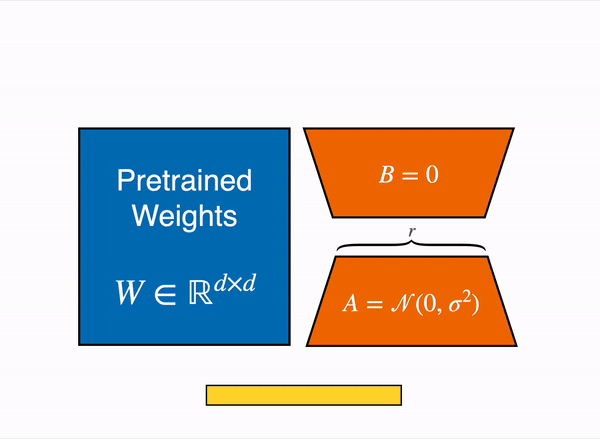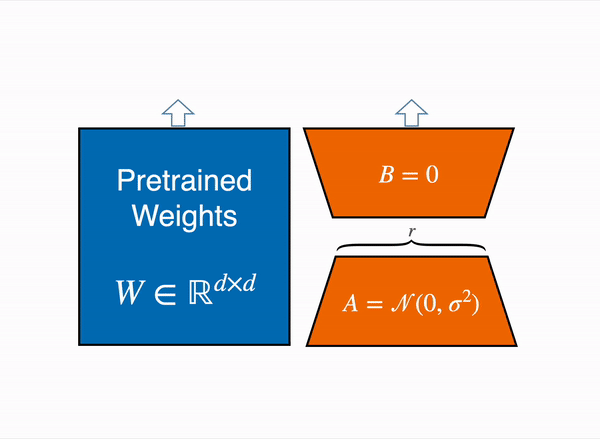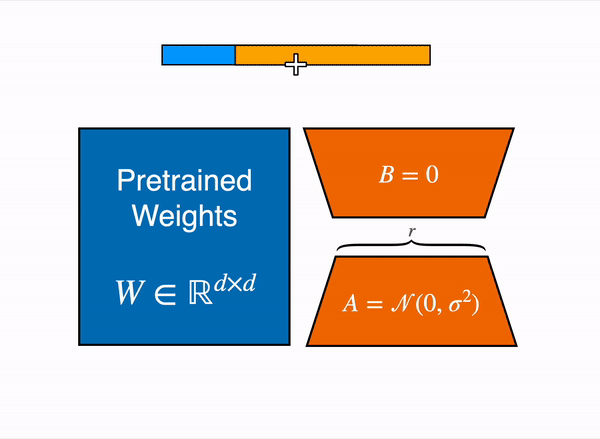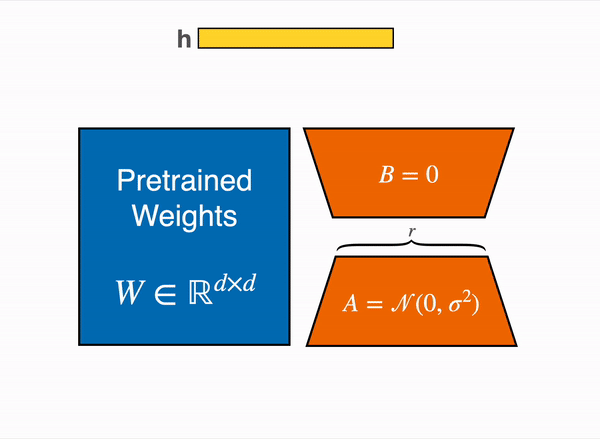
Given the input x
Output h = W0x + ∆W x = W0x + BAx
- QLora
- An extension of LoRA that further introduces quantization to enhance parameter efficiency during fine-tuning.
- Model quantization: Reduce the precision of a model's weights and activations, typically by converting them from high-precision floating-point numbers to lower-precision integers.

Model Quantization
Unsloth Fine-Tuning
- Open-source platform that accelerates and optimizes the process of fine-tuning large language models (LLMs).
- Key Advantages
- 2x faster training speed with 70% less VRAM compared to the regular Hugging Face training.
- Supports efficient training methods such as:
- QLoRA (Quantized LoRA) for low-VRAM fine-tuning
- 4-bit and 8-bit training
- Gradient checkpointing for large models
- A technique that reduces memory consumption during model training by strategically saving only a subset of intermediate activations (outputs of each layer)
- During the backward pass, when an activation is needed but hasn't been stored, the model recomputes it on the fly, starting from the nearest available checkpoint.
- Works across many model types (LLMs, multimodal models, TTS, BERT, etc.)
How is Unsloth Faster?
| Technique |
Benefit |
| Manual autograd & optimized matrix multiplication chaining |
Reduces unnecessary compute overhead |
| All performance-critical kernels rewritten in OpenAI Triton |
Faster training and reduced GPU memory usage |
Hands-On Time!