
Tensors 可以說是構成所有 Deep Learning 要素的基礎,幾乎所有東西 (parameters, gradients, optimizer state, data, activations) 都是以 tensor 的形式儲存,而 tensor 裡面的數值又是以 floating point numbers 的形式儲存。
記憶體的使用量會由 (i) 儲存多少數值 (ii) 每個數值的 data type 決定,因此了解這些 floating number type 對理解 Deep Learnging 中記憶體的使用至關重要。
float32 (也稱為 fp32 or single precision)是多數計算框架預設的數值型別。在科學計算中, float32 通常會被當作baseline,但一些情況下也會使用 double precison (float64)。
一個 fp32 的 32 bits 分配為:1 bit 符號 (sign) + 8 bits 指數 (exponent,決定 dynamic range) + 23 bits 小數 (fraction,決定 resolution)
由於這是預設型別,我們往往會忽略掉 fp32 對記憶體的使用有多大。一個 fp32 的數值會消耗掉 4 bytes 的空間,以 GPT-3 的一個 feedforward layer (12288 * 4, 12288) 為例,fp32 會直接用掉 2.3 GB 的記憶體!
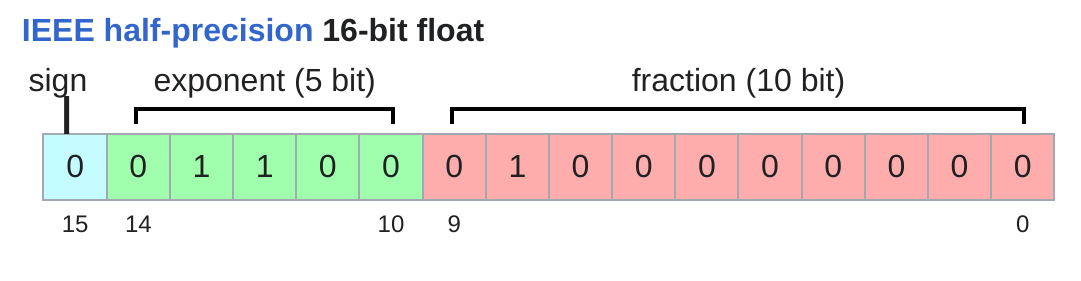
float16 (也稱為 fp16 或 half precision) 可以減少一半的記憶體空間,但代價就是比起 fp32 , dynamic range 大幅減少,這會導致訓練過程中容易遇到數值不穩定的情況 (ex: 在 fp16 的精度下, $10^{-8}$ 無法表示,會導致 underflow 而直接歸0!)
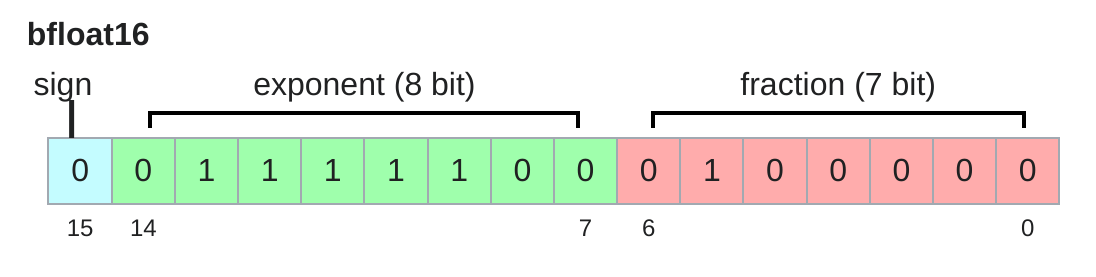
bfloat16 (brain floating point) 是 Google Brain 為了解決 fp16 數值不穩定的問題,在2018年所提出新的一種 data type。簡單來說,bfloat16 其實就是將 fp16 fraction 部分的 3 bit 分配給 exponent。因此 bfloat16 在記憶體使用量 和 fp16 相同的情況下可以有著和 fp32 一樣的 dynamic ranges。
雖然 bf16 適合用來做矩陣乘法運算(因為深度學習對小數點後的精確度容錯率高),但「不能將 bf16 用於儲存 optimizer states 和模型參數 (parameters)」,否則訓練會徹底崩潰
可以透過下方的程式進一步了解不同 data type 的dynamic ranges 和 memory usage