GitHub - lucidrains/CoCa-pytorch: Implementation of CoCa, Contrastive Captioners are Image-Text Foundation Models, in Pytorch
Abstract
1. Introduction
2. Related Work
-
Vision Pretraining
- Pretraining ConvNets or Transformers → visual recognition problem 해결의 주요 전략
- BEiT
- a masked image modeling task following BERT 제안
- quantized visual token ids을 prediction target으로 활용
- MAE, SimMIM
- remove the need for an image tokenizer
- directly use a light-weight decoder or projection layer to regress pixel values
- 이런 모델들은 joint reasoning (image+text)를 필요로 하는 태스크에 적용 불가
-
Vision-Langauage Pretraining
- LXMERT, UNITER, ViLBERT
- encode vision and language in a fusion model
- visual repersentation 추출을 위해 Fast(er) R-CNN 사용
- ViLT, VLMo
- vision & language transformers 결합 → multimodal transformer 학습
-
Image-Text Foundation Models
Dual encoder
- CLIP & ALIGN
- Florence
- LiT & BASIC
- Image-Text Foundation Models :
Encoder - Decoder
- ALBEF : contrastive loss ( w/ MLM ) 과 dual-encoder design 결합
<aside>
💡 (1) CoCa는 forward and backward propagation를 오직 한 번 수행
(ALBEF는 2번)
(2) CoCa is trained from scratch on the two objectives
(3) 자연어 생성에 decoder 구조(w/generative loss)가 선호되고 image captioning과 zero-shot learning을 직접적으로 가능하게 함
</aside>
3. Approach
3.1 Natural Language Supervision
Single Encoder Classification
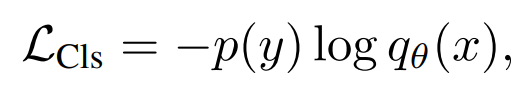
이러한 annotation은 discrete class vector로 매핑 되어있기 때문에 cross entropy로 Loss를 구하는 것이 효과적
→ generic visual representation extractor
Dual-Encoder Contrastive Learning