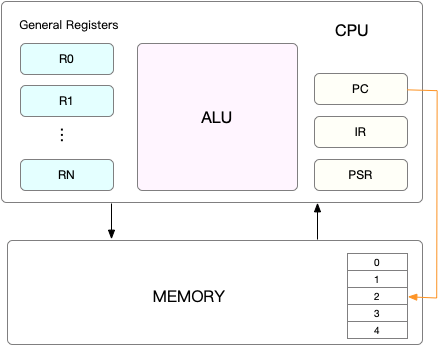
CPU 的上下文包括 CPU寄存器, 和 程序计数器
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做 CPU 上下文。
知道了什么是 CPU 上下文,我想你也很容易理解 CPU 上下文切换。CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
根据任务的不同. CPU上下文切换可以如下场景: 进程上下文切换, 线程上下文切换 和 中断上下文切换
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中, CPU 特权等级的 Ring 0 和 Ring 3。
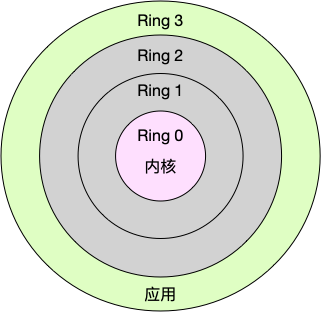
换个角度看,也就是说,进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。
从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容,并调用 write() 将内容写到标准输出,最后再调用 close() 关闭文件。
那么,系统调用的过程有没有发生 CPU 上下文的切换呢?答案自然是肯定的。
CPU 寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。
而系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换。
不过,需要注意的是,系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。这跟我们通常所说的进程上下文切换是不一样的: