In sports betting, bookmakers odds are shaped by public betting biases (heavy favoritism toward well-known teams), liquidity-driven price discovery, and a built-in margin. This frequently creates persistent inefficiencies where the true probability of match outcomes diverges from the market’s implied probabilities. The goal was to develop a repeatable, quantifiable edge over the market that did not rely on subjective intuition or game-watching, but instead on an objective algorithmic approach. This was driven by the desire to identify mispriced opportunities in high-liquidity markets (1X2, Over/Under 2.5, Asian Handicap, etc.) in a sport known for high randomness, where even post-match Expected Goals (xG) explains only ~20% of actual goal variance (more on this later). So here is what I did:
I built a three-phase pipeline that turns chaotic raw data into a calibrated “fair line” for every match. The architecture is deliberately transparent at the conceptual level while keeping the exact proprietary algorithms confidential.
Data quality determines everything, as “garbage in, garbage out”. For that reason, I created a fully automated, multi-stage scraping and cleaning system centered on various sources.
The result is a clean, interconnected historical database where every player action is contextualized and traceable.
Two sequential modeling stages turn raw player performances into context-aware xG projections.
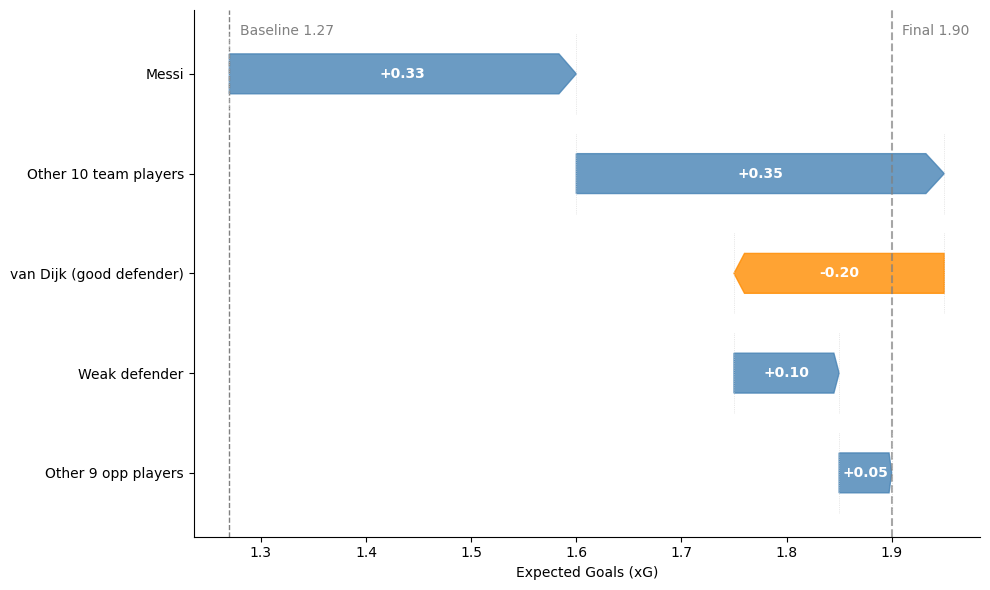
A purpose-built machine-learning model analyzes every player’s historical match data to learn two latent values per player:
These coefficients are matchup-aware: a high-offensive forward facing a low-defensive defender increases the attacking team’s projected output. This creates a dynamic “player library” that automatically adjusts for injuries, form changes, or squad rotation.