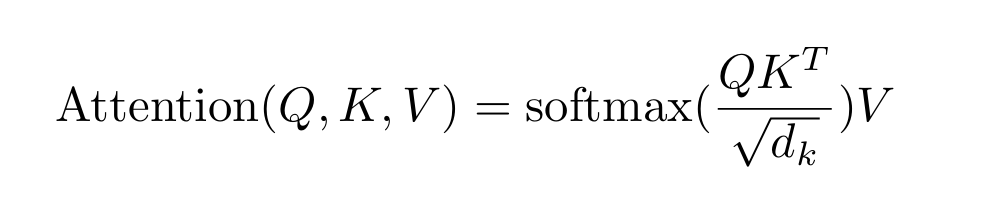
<aside>
`TLDR;
Transformers use attention to process entire sequences simultaneously, bypassing the limitations of sequential RNNs.
Attention mechanisms work by comparing queries to keys and using the results to weight the values, allowing models to focus on relevant information.
Multi-head attention, positional encodings, and residual connections are key design choices that make Transformers powerful and scalable.
The evolution from RNNs to Transformers - sparked by early attention ideas - has paved the way for SOTA models in NLP, computer vision, and beyond.`
</aside>
Imagine you’re at a busy party - the so‐called “cocktail party effect.” You focus on a friend’s voice amidst the chatter. In ML, this ability to selectively “listen” is what attention mechanisms enable. Early neural networks struggled with long sentences and complex relationships. The concept of “Attention” first emerged in machine translation, where models had to decide which words to “focus on” to translate a sentence correctly.
Imagine reading a complex paragraph: instead of trying to remember every single word equally, you naturally focus on the most relevant sentences to understand the meaning. In Transformers, each word (or token) is transformed into three vectors:
The model computes how “compatible” a query is with each key using a dot product, scales the result (to prevent overly large numbers), and then applies a softmax function. This converts raw scores into probabilities (attention weights) that determine how much each word should contribute when forming a new representation. Mathematically, it looks like this:
This self-attention mechanism means every word can “look at” every other word , capturing context, syntax, and even distant relationships that older models struggled to remember.

Encoder–Decoder Structure
The Transformer is built on a classic encoder–decoder model:
Both parts are built from stacked layers that use attention and feed-forward networks, but they differ slightly:
Multi-Head Attention