稳定性保障,是一切技术工作的出发点和落脚点,也是 IT 工作最核心的价值体现,当然也是技术人员最容易“翻车”的阴沟。8个稳定性保障锦囊,分享给各位技术人员择机使用。
没有度量就没有改进。Google SRE 曾在其工程实践中,就引入了针对服务可靠性的预算机制,即「Budget」的概念。技术团队和业务团队就服务不可用时长的额度,制定合理的目标,进而指导技术投资、稳定性保障、业务发展三者的全局最优解法。技术方制定稳定性的度量指标,一个关键出发点是“业务方要听的懂”。
我们可以将度量指标进行更进一步的抽象,分别从外部用户视角和从内部系统视角,全面的看待整体的可用性,甚至某种意义来讲,从外部用户视角看到的稳定性统计结果更有说服力,更有价值。暂且把从外部用户视角对系统可用性的度量指标称之为「北极星指标」。通过北极星指标的实时变化趋势,技术和业务团队可以全面的了解系统的运行状态,当发生全局故障的时刻,也可以让所有参与者能够清楚知晓对核心业务的影响面,进而对故障级别、应急处置优先级有统一的认知。北极星本质上,就是在从用户的视角,来整体看待复杂系统的稳定性。
举几个例子:
对于类似 zoom 这样的在线会议业务,其北极星指标可以定义为「1分钟内的参与会议的方数」;对于电商业务,其北极星指标可以定义为「1分钟内的交易笔数」;对于游戏业务,其北极星指标可以是 「1分钟内的同时在线游戏人数」;对于类似滴滴这样的出行业务,其北极星指标可以是「1分钟内的呼叫次数」「1分钟内处于行程中的订单数」;对于直播类的业务,其北极星指标可以是「1分钟内的主播在线数」「1分钟内的观众在线数」「1分钟内的打赏总金额」等;
从故障发现和定位的角度,一旦这些北极星指标发生了异常波动,就代表了核心业务受到了影响,该事件应该要第一时间被响应并上升,故障应急小组第一时间就位,相关支撑系统的工程师也要被 involve 进来。这种方法可以确保技术团队在业务受损的第一时间就能感知到,起到了故障发现兜底的作用。
同时,北极星指标经过一段时间的运行,其异常的时间、正常的时间,本身就是一个很客观的度量我们系统是否稳定的依据,作为技术团队和业务方沟通的桥梁,是最合适不过了。一年到头,稳定性好与坏,不是技术团队自说自话,从外部用户的视角,用北极星指标的统计结果更客观。
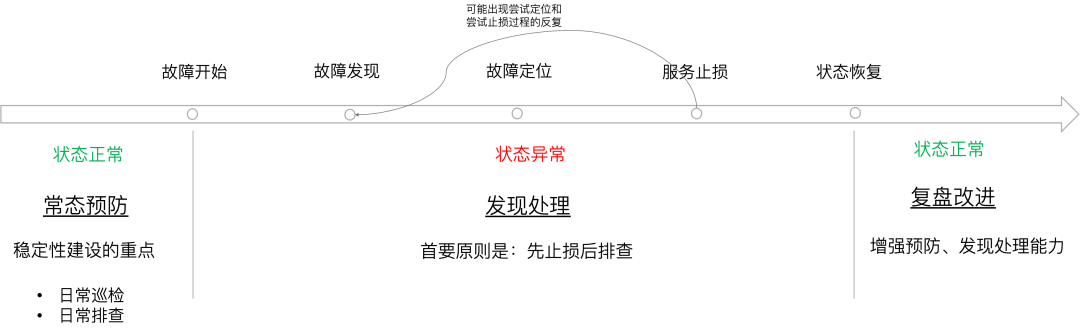
故障发现、定位、止损,是稳定性保障闭环中最紧迫、最关键的环节,通常技术人员会做的事情是从各个维度收集『信息』以辅助决策: