
hideBreadcrumbs: true
bottomNavigator: null
title: "타이타닉호 데이터셋 실습 1탄 : 데이터에서 두 집단을 구분하는 특성 찾기"
description: "이번 글에서는 타이타닉호에 탑승한 사람 중 살아남은 사람과 죽은 사람을 구분하고자 할 때, 탑승자의 어떤 속성(변수)이 두 집단을 구분하는데 요긴한 변수인지 확인하는 방법에 대해 알아 보겠습니다."
<head>
<link rel="canonical" href="<https://community.heartcount.io/ko/titanic-dataset-1/>" />
</head>
두 집단을 구분하는 특성 찾기 관련 시리즈
실무 현장에서, 두 집단을 구분짓는 주요 특성을 데이터에서 찾아야 하는 경우가 종종 있습니다. 인사부서에서 고성과자와 저성과자를 구분하는 주요 특성을 파악하고자 하는 경우, 운영부서에서 매출이 좋은 매장들과 그렇지 못한 매장들의 차이가 어디서 비롯되는지 이해하고자 하는 경우, 마케팅 부서에서 최근 캠페인에 반응한 사람들의 세그먼트 특성을 (반응하지 않은 사람들과 비교하여) 파악해야 하는 경우 등이 그렇습니다.
이번 글에서는 타이타닉호에 탑승한 사람 중 살아남은 사람과 죽은 사람을 구분하고자 할 때, 탑승자의 어떤 속성(변수)이 두 집단을 구분하는데 요긴한 변수인지 확인하는 방법에 대해 알아 보겠습니다.
아래 그림에서 생존자를 파랑색, 사망자를 노랑색으로 구분한 후 나이에 따른 각 집단의 분포를 시각화했다고 가정해 보겠습니다. 생존자 집단의 나이가 전체적으로 많은 것(파랑색 집단의 나이 분포가 오른쪽에 치우쳐 있음)을 쉽게 확인할 수 있고, 나이 변수가 두 집단을 구분하는데 유용할 수 있겠다고 짐작할 수 있습니다.
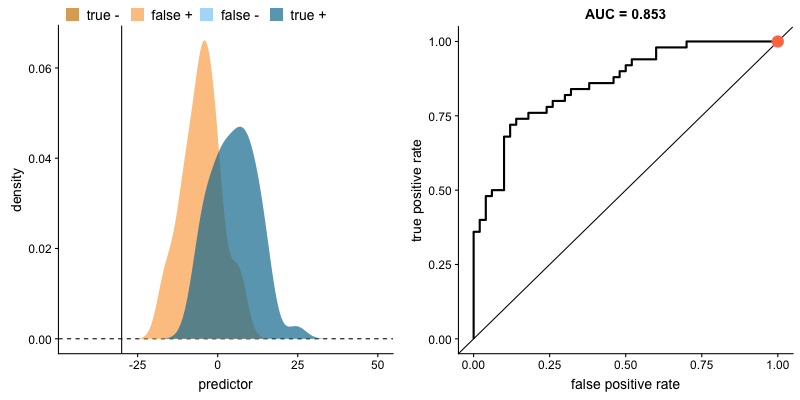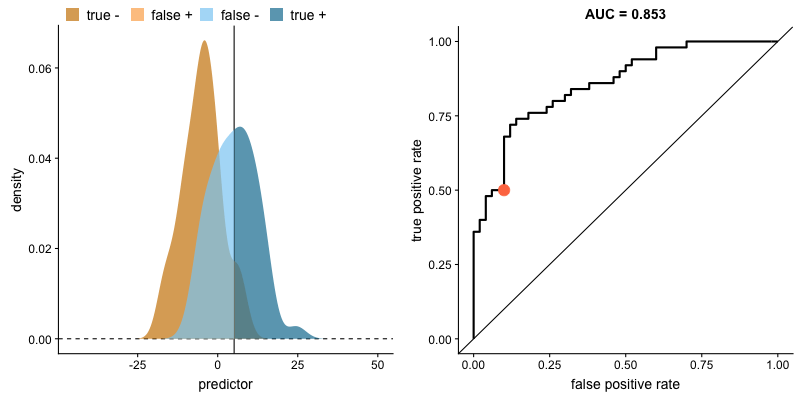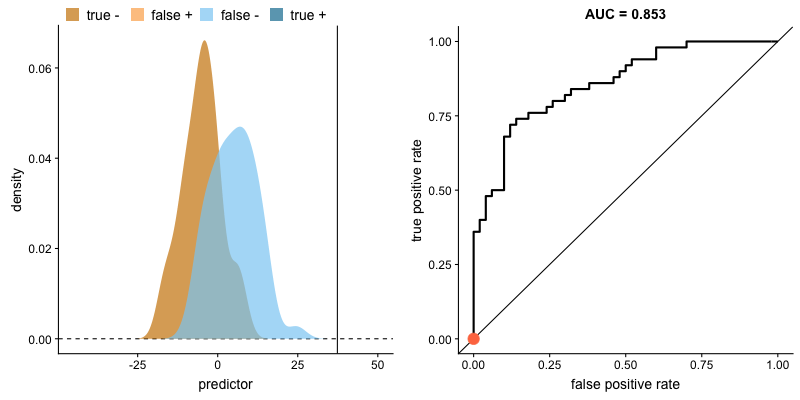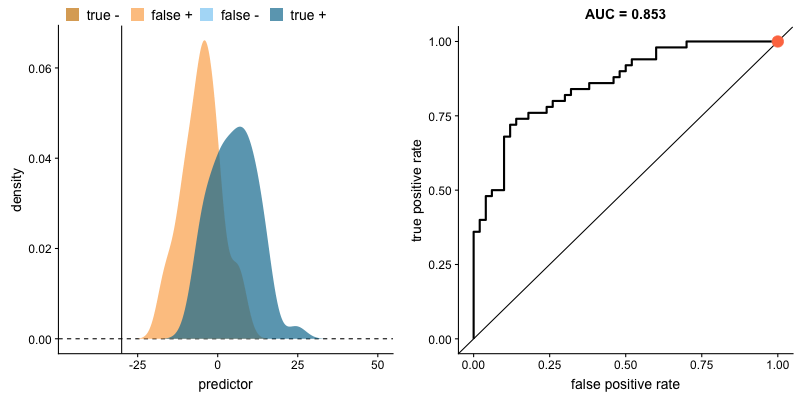
다만, 나이 말고도 성별, 탑승권의 종류 등 두 집단을 구분할 때 사용할 수 있는 속성(변수)이 많다고 할 때, 이런 속성들의 상대적 중요도를 육안으로만 파악하는데는 한계가 있습니다.
<aside> 💡 *AUC는 Area Under Curve(곡선 아래의 면적)의 약어로, 주어진 두 집단의 분포에서 생존, 사망 집단을 구분하는 기준점(cutoff, 좌측의 수직 직선)을 얼마로(20세, 25세 등) 설정하느냐에 따라, True Positive(생존했을 거라 예측했고 실제로도 생존한 경우), False Positive(생존했을 거라 했는데 실제는 사망한 경우) 비율이 달라지는 위치를 좌표 상에 표기 한 후, 해당 점들을 이은 선(ROC curve라고 함) 아래의 면적을 나타냅니다.
</aside>