paper- language model are unsupervised multitask learners (gpt2)
-gpt2 weights are public and llama too
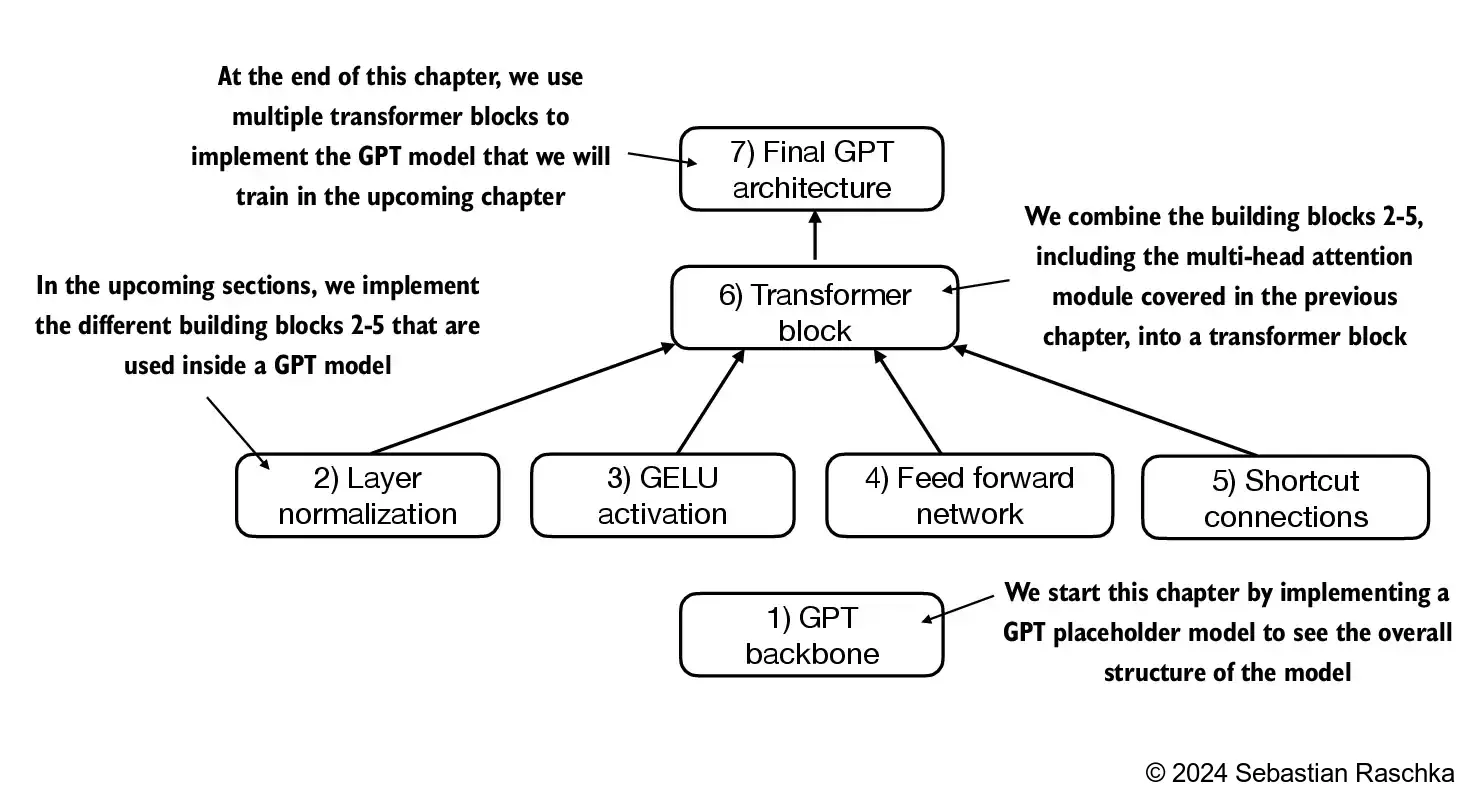
we will code the arch of gpt2 model
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-Key-Value bias
}
layer norm improves the stability and efficiency of nn training
main idea of layer norm: adjust output of nn to have mean zero and normalize variance to 1
applied both before and after multi-head attention module within transformer block
this affect training —> layer normalization keeps gradient stable
this delays convergence → layer norm prevents this