https://cloud.tencent.com/document/product/1709/94945
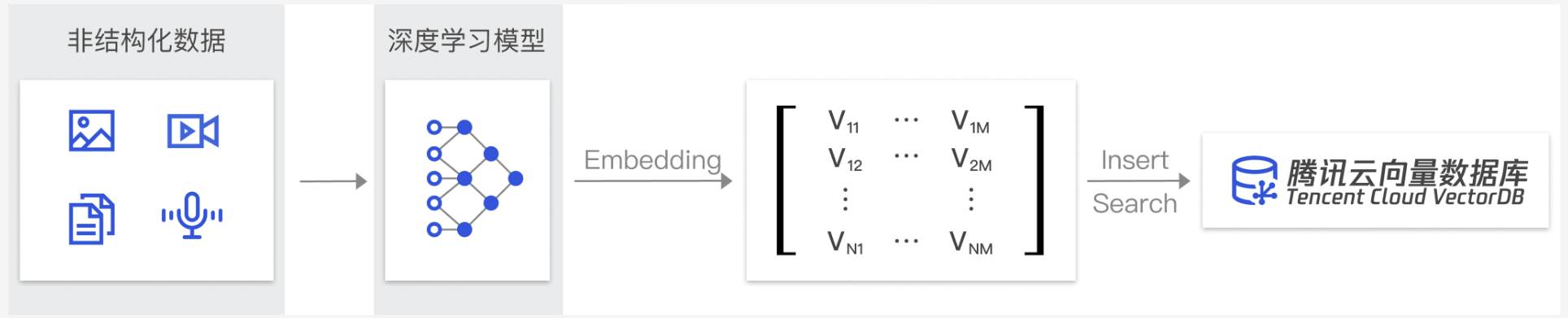
随着互联网的普及,越来越多的非结构化数据如电子邮件、图像、音视频和文本等变得普遍。为了让计算机能够理解和处理这些非结构化数据,使用嵌入技术将这些数据转换为向量形式。
腾讯云向量数据库(Tencent Cloud VectorDB)是一款全托管的自研企业级分布式数据库服务,专用于存储、索引、检索、管理由深度神经网络或其他机器学习模型生成的大量多维嵌入向量。作为专门为处理输入向量查询而设计的数据库,它支持多种索引类型和相似度计算方法,单索引支持10亿级向量规模,高达百万级 QPS 及毫秒级查询延迟。不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、NLP 服务、计算机视觉、智能客服等 AI 领域。
如果您不熟悉向量数据库和相似性搜索领域,请优先阅读以下基本概念,便于您对向量数据库有一个初步的了解。更多名词解释,请阅读 关键概念。
什么是向量?
向量是指在数学和物理中用来表示大小和方向的量。它由一组有序的数值组成,这些数值代表了向量在每个坐标轴上的分量。
什么是非结构化数据?
非结构化数据,是指图像、文本、音频等数据。与结构化数据相比,非结构化数据不遵循预定义模型或组织方式,通常更难以处理和分析。
什么是 AI 中的向量表示?
当我们处理非结构化数据时,需要将其转换为计算机可以理解和处理的形式。向量表示是一种将非结构化数据转换为嵌入向量的技术,通过多维度向量数值表述某个对象或事物的属性或者特征。腾讯云向量数据库提供的模型能力,目前在开发调试中。具体上线时间,请关注 产品动态。
什么是向量相似性检索?
向量检索是一种基于向量空间模型的信息检索方法。向量数据库通过相似度计算方法计算两个向量之间的相似距离来分析它们之间的相关性。如果两个嵌入向量非常相似,则意味着原始数据源也相似。
腾讯云向量数据库作为一种专门存储和检索向量数据的服务提供给用户, 在高性能、高可用、大规模、低成本、简单易用、稳定可靠、智能运维等方面体现出显著优势。 具体信息,请参见 产品优势。
在建表时,需指定向量的 索引类型(如 HNSW 等)与 相似度计算方法。数据库存储的向量将会按照指定的索引类型进行索引。那么,在向量检索时,便会依据索引并使用已选择的相似性计算方法进行匹配,快速高效地获取目标向量。如果不指定索引类型,向量数据库将默认进行暴力搜索。具体支持的索引类型和计算方法的详细介绍,请参见 索引与计算。