在优先级队列中,数据的出队顺序不是先进先出,而是 按照优先级来,优先级最高的,最先出队。
1.合并有序小文件 假设我们有100个小文件,每个文件的大小是100MB,每个文件中存储的都是有序的字符串。我们希望将这些100个小文件合并成一个有序的大文件。这里就会用 到优先级队列。
整体思路有点像归并排序中的合并函数。我们从这100个文件中,各取第一个字符串,放入数组中,然后比较大小,把最小的那个字符串放入合并后的大文件中, 并从数组中删除。 假设,这个最小的字符串来自于13.txt这个小文件,我们就再从这个小文件取下一个字符串,并且放到数组中,重新比较大小,并且选择最小的放入合并后的大文 件,并且将它从数组中删除。依次类推,直到所有的文件中的数据都放入到大文件为止。
我们将从小文件中取出来的字符串放入到小顶堆中,那堆顶的元素,也就是优先级队列队首的元素,就是最小的字 符串。我们将这个字符串放入到大文件中,并将其从堆中删除。然后再从小文件中取出下一个字符串,放入到堆中。循环这个过程,就可以将100个小文件中的数 据依次放入到大文件中。
例题: LeetCode 23题 合并K个有序链表
我把这种求Top K的问题抽象成两类。一类是针对静态数据集合,也就是说数据集合事先确定,不会再变。另一类是针对动态数据集合,也就是说数据集合事先并 不确定,有数据动态地加入到集合中。
针对静态数据,如何在一个包含n个数据的数组中,查找前K大数据呢?我们可以维护一个大小为K的小顶堆,顺序遍历数组,从数组中取出取数据与堆顶元素比 较。如果比堆顶元素大,我们就把堆顶元素删除,并且将这个元素插入到堆中;如果比堆顶元素小,则不做处理,继续遍历数组。这样等数组中的数据都遍历完 之后,堆中的数据就是前K大数据了。 遍历数组需要O(n)的时间复杂度,一次堆化操作需要O(logK)的时间复杂度,所以最坏情况下,n个元素都入堆一次,所以时间复杂度就是O(nlogK)。
针对动态数据求得Top K就是实时Top K。举一个例子。一个数据集合中有两个操作,一个是添加数据,另一个询问当前的前K大数据。 如果每次询问前K大数据,我们都基于当前的数据重新计算的话,那时间复杂度就是O(nlogK),n表示当前的数据的大小。实际上,我们可以一直都维护一个K大小 的小顶堆,当有数据被添加到集合中时,我们就拿它与堆顶的元素对比。如果比堆顶元素大,我们就把堆顶元素删除,并且将这个元素插入到堆中;如果比堆顶 元素小,则不做处理。这样,无论任何时候需要查询当前的前K大数据,都可以立刻返回
例题: LeetCode 215题 数组中的第K个最大元素
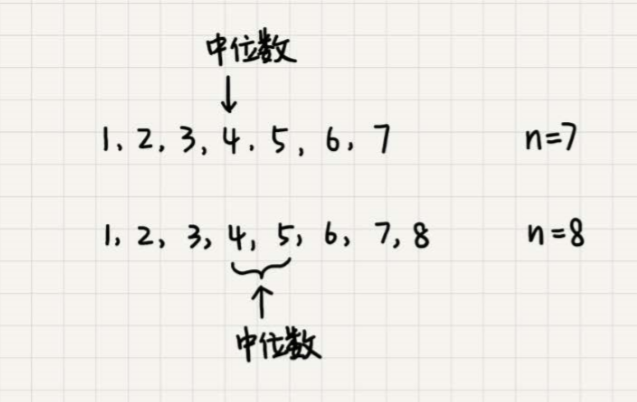
对于一组静态数据,中位数是固定的,我们可以先排序,第n/2个数据就是中位数。每次询问中位数的时候,我们直接返回这个固定的值就好了。所以, 尽管排序的代价比较大,但是边际成本会很小。但是,如果我们面对的是动态数据集合,中位数在不停地变动,如果再用先排序的方法,每次询问中位数的时 候,都要先进行排序,那效率就不高了。 借助堆这种数据结构,我们不用排序,就可以非常高效地实现求中位数操作。
我们需要维护两个堆,一个大顶堆,一个小顶堆。大顶堆中存储前半部分数据,小顶堆中存储后半部分数据,且小顶堆中的数据都大于大顶堆中的数据。 也就是说,如果有n个数据,n是偶数,我们从小到大排序,那前n/2个数据存储在大顶堆中,后n/2个数据存储在小顶堆中。这样,大顶堆中的 堆顶元素就是我们要找的中位数。如果n是奇数,情况是类似的,大顶堆就存储n/2+1个数据,小顶堆中就存储n/2个数据。
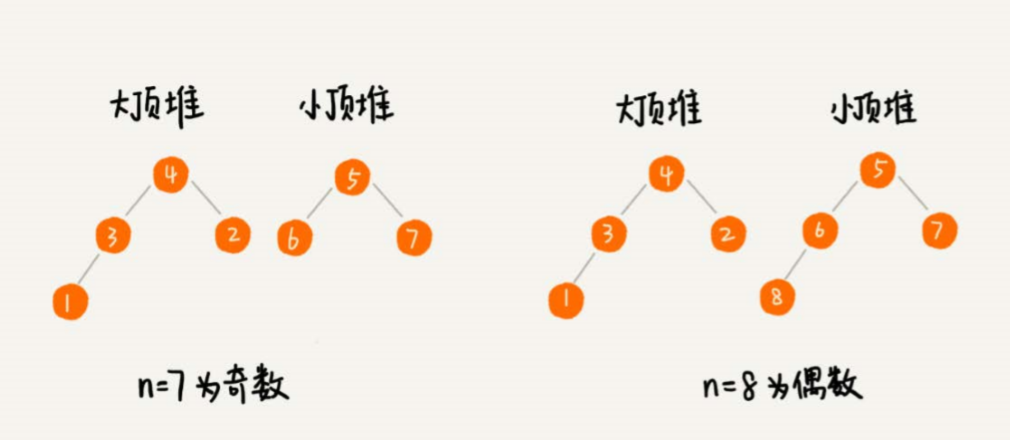
当数据为静态的时候
当数据是动态变化的时候,新添加一个数据的时候,如果新加入的数据小于等于大顶堆的堆顶元素,我们就将这个新数据插入到大顶堆;如果新加入的数据大于等于小顶堆的堆顶元素,我们就将这个新数据插入到 小顶堆。 这个时候就有可能出现,两个堆中的数据个数不符合前面约定的情况:如果n是偶数,两个堆中的数据个数都是n/2;如果n是奇数,大顶堆有n/2+1个数据,小顶堆有n/2个数据。这个时候,我们可以从一个堆中不停地将堆顶元素移动到另一个堆,通过这样的调整,来让两个堆中的数据满足上 面的约定。
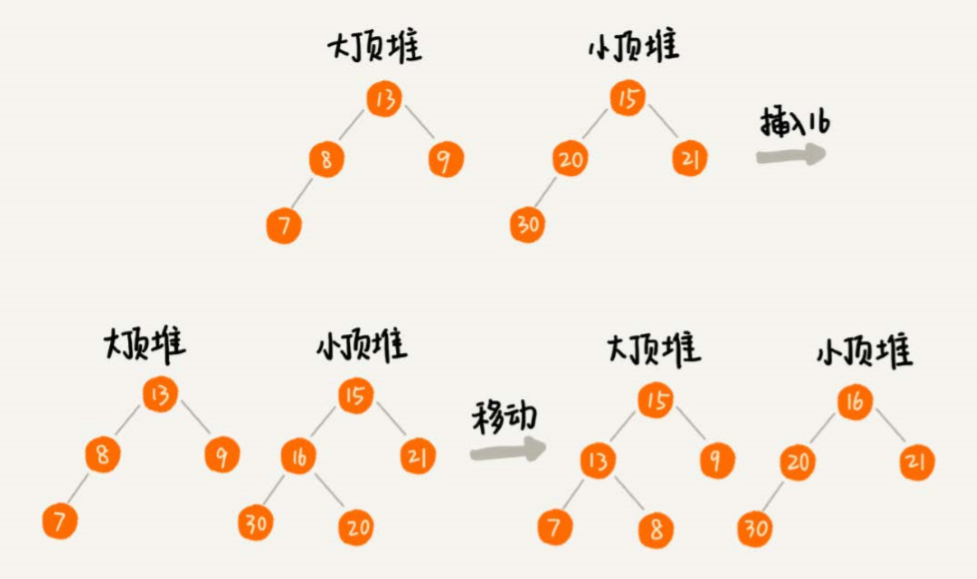
当数据为动态的时候